Kesakode
Kesakode is a remote hash lookup service exclusive to Malcat users and tightly integrated inside Malcat’s UI (cf. Kesakode lookup). It can be used to match known functions, strings and constant sets against a database of known clean, malware and library files. The Kesakode service can be used in various situation, such as:
identify unpacked (e.g. a sandbox dump) malware samples
show similarities shared between malware families
assist in the creation of better Yara rules
speed up reverse engineering by identifying know libraries / runtime code
During the whole process, only hashes are sent to our platform, your sample never leaves your computer. If you only use Offline Kesakode, nothing leaves your computer at all, even better!
Note
To use the Kesakode service, you need a running license of Malcat (see Full & Pro versions).
How does it work?
While there is some technicality behind the scene, the main idea fueling Kesakode is rather simple and will be summarized below.
Indexing process
We have built over the last months a big library of 300+ of the most recent malware families, alongside several millions of known clean programs and libraries. Add to that the impressive 2000+ malware families corpus of Malpedia, and you get a reasonable training dataset. For each sample, three sets of features have been extracted:
Hashes of every interesting function found in the sample, with their absolute offsets masked out (to cope with code relocation)
Hashes of every interesting string found in the sample (we use Malcat’s scoring system there)
A single fuzzy hash computed over the list of interesting code immediates and data constants identified by our Constant scanner
Hashes are stored in a huge relational database, and linked to their corresponding sample.
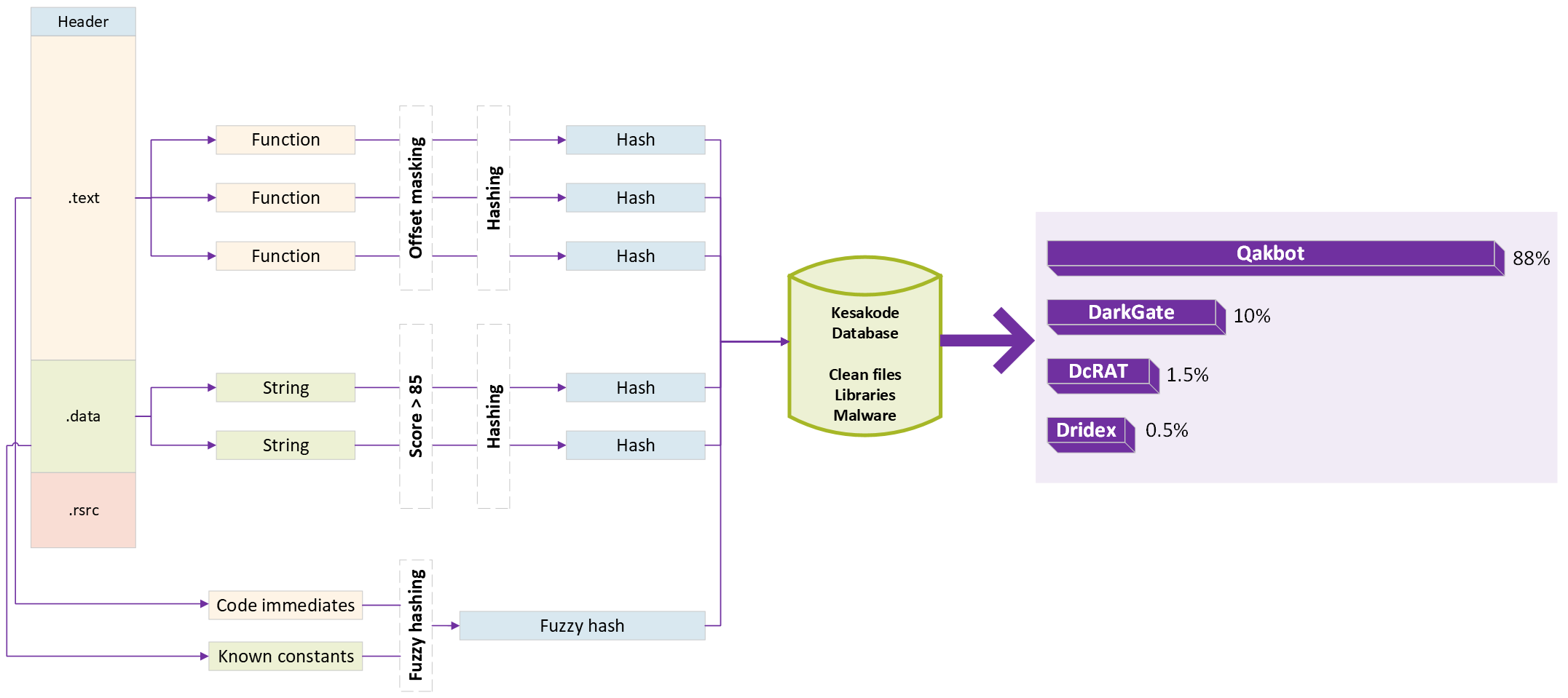
How Kesakode computes similarities for your file
At query time
When you make a Kesakode query from within the Kesakode lookup view, the same three sets of hashes are computed and sent to our matching service.
For function and string hashes, our cloud service will simply query the database and try to recollect if and where we have seen this hash before. Then a simple decision tree is used:
If we have seen a function hash in a library, it will be labelled as LIBRARY code and the name of the library will be returned
Otherwise if we have seen the string/function hash in a clean program, we label the hash as CLEAN
Finally, if the hash was only seen in malware, it is labelled as MALICIOUS and Kesakode returns all the malware family names where it was found
For code immediates and data constants, we take a different approach though, as indexing every constant/immediate found in programs would not be technically achievable. Instead, we only focus on malicious samples there, and store for each sample a single fuzzy hash summarizing the whole constant/immediate sets in 128 bytes. Fuzzy hashes allow for fast fixed-time comparisons of two constants sets and greatly improve performance. At query time, the constants fuzzy hash is compared to its nearest neighbours and all malware families having a similarity score greater than 80% are returned.
All results are finally display in the Kesakode lookup view, where you can see every matching function and string. A global likelihood score is also computed for matching malware families to help you make the final call.
Offline Kesakode
Because not every machine is connected to the internet, Full & Pro versions of Malcat embed a small offline Kesakode database, stored in data/kesakode/. This database is limited to malware hashes (i.e. no library/clean classification) and is updated with every Malcat release (so not very often). It is used by Malcat at analysis time to perform a preliminary kesakode lookup.
This process is completely offline and does not consume any token. But keep in mind it is less precise than an online query. Also another limitation is that it cannot be Run Malcat from your python interpreter, i.e. not available in headless mode. If you want to use it to perform batch scans, please contact us and we will work a OEM license out.
And does it work?
It works well! Malware are notably tricky and try to camouflage themselves by using deception techniques such as code obfuscation or data/string encryption. By using three different sets of features (functions, strings and constants), Kesakode is still able to identify the vast majority of the malware samples one way or another. In fact, the only limiting factor is our database. But with your help, this factor can be alleviated by Submitting false positives/negatives requests!
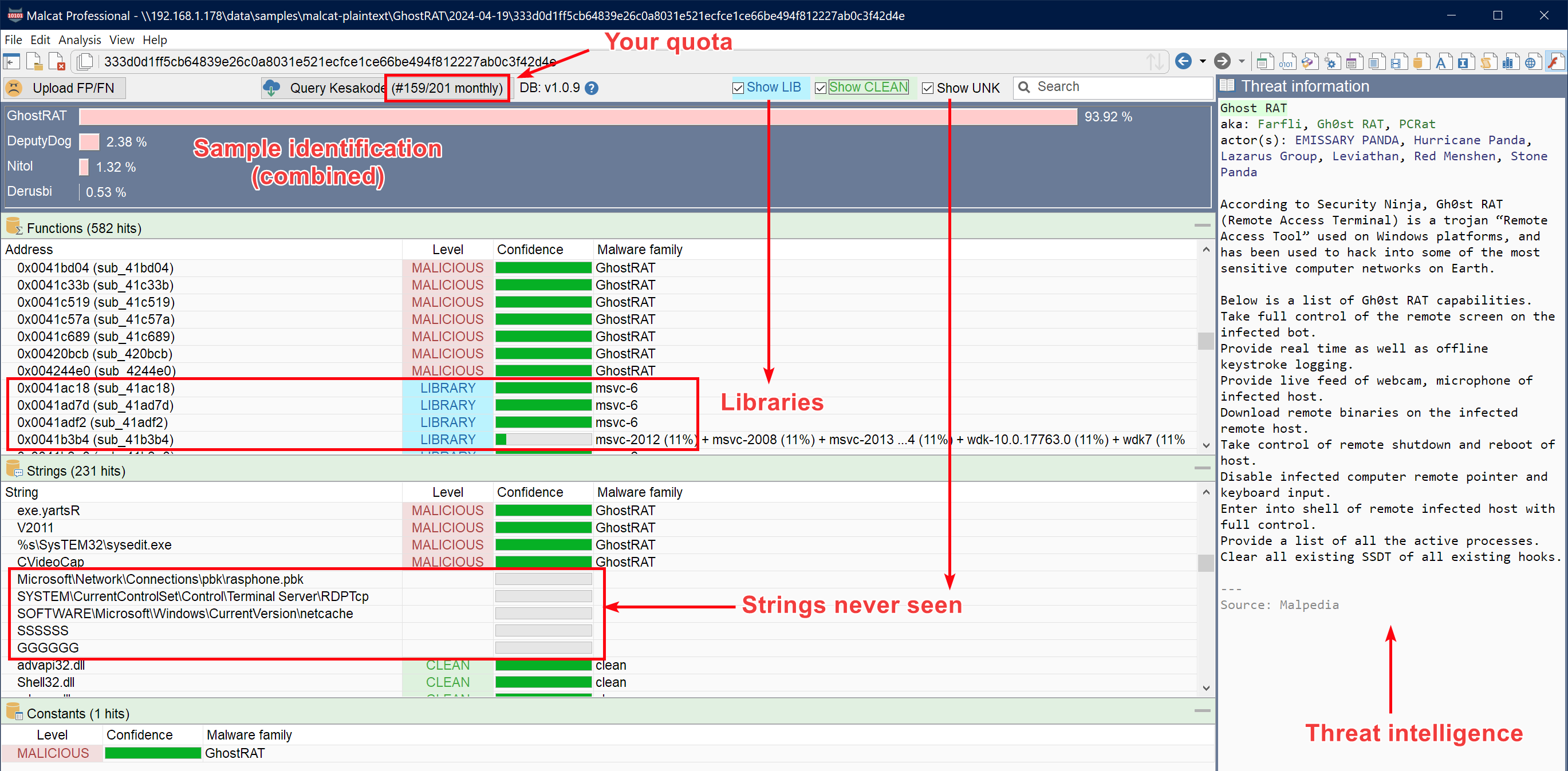
Kesakode helping to identify your sample
Regarding performances, you can expect your typical online lookup query to take between 1 and 4 seconds, plus the roundtrip time needed to contact the server when running an online query. Offline scans are way faster and can range between 100ms and 1s. This can of course vary depending on the number of functions and strings found in your program.
If you want to learn more, have a look at a few use cases of the Kesakode service below.
Use cases
Whether you are a malware analyst, detection engineer or a more casual reverse engineer, Kesakode lookups can help you save time in a few situations. We’ll see how below.
Malware identification
The main and most obvious usage than can be made of Kesakode is malware identification, i.e answering the question: to which malware family does this sample belong?
While there exist a lot of public Yara rules on the Internet that can identify malware families, finding good Yara rules is another story. Yara rules sets can be incomplete and/or can get outdated quickly if the rules are poorly written. Kesakode can help you there, as it can identify samples using more patterns than your standard Yara rule. And if we don’t have a particular family in our database, Submitting false positives/negatives is just a couple of clicks away and require less effort than writing your own Yara rule! Note that Kesakode will only work on unpacked/dumped samples, as attributing packers/crypters to a single malware family is often not possible. You can for instance run Kesakode on process dumps issued by the Triage sandbox.
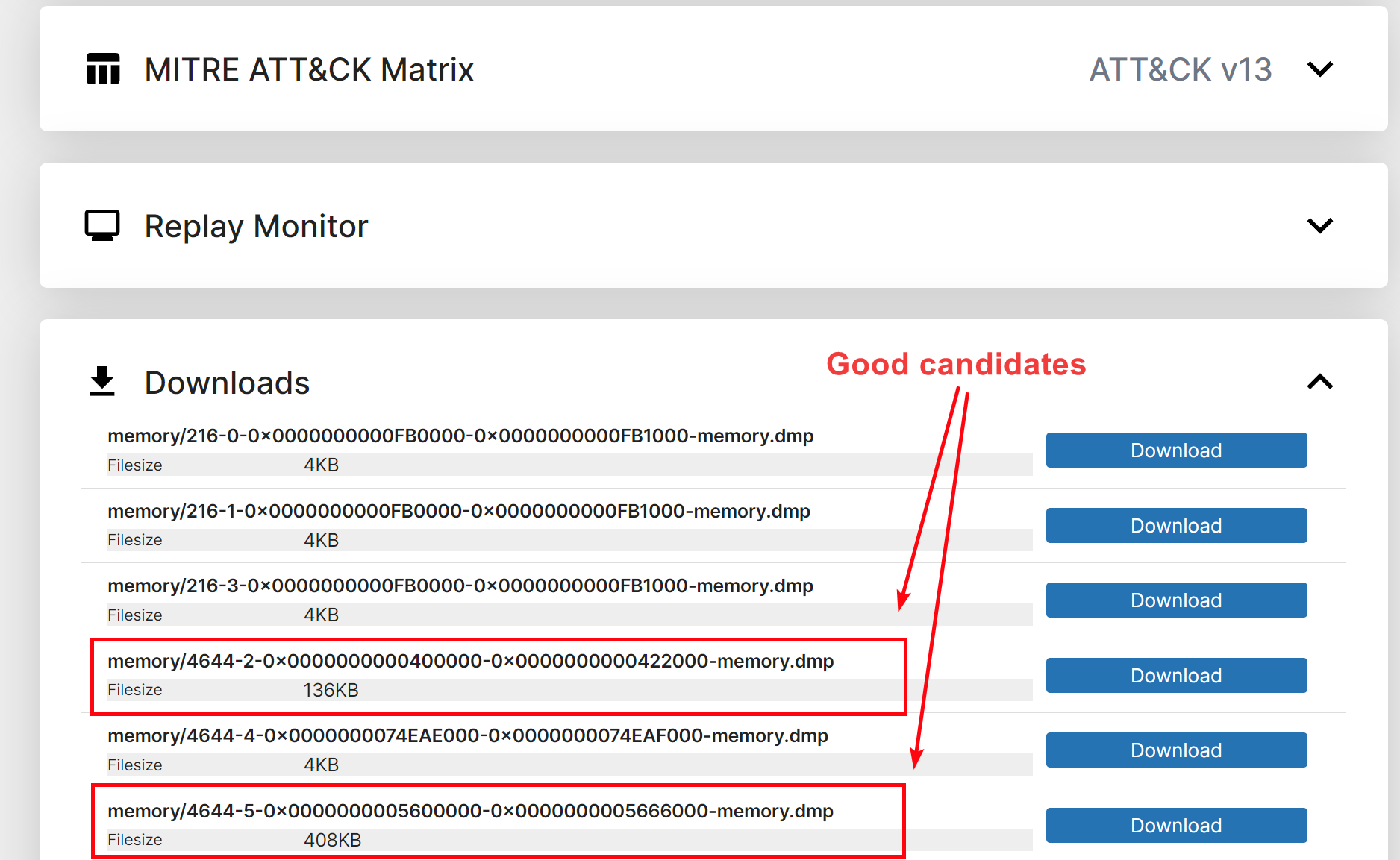
Tria.ge Sandbox dumps are good targets for precise malware identification using Kesakode
Kesakode lookups can also help you spot similarities between malware families, information that Yara rules often fail to provide. You’ll be able to see which function and/or string of your sample is used in other malware families, and use this information to deduce the family tree of the malware family.
Detection engineering
If you’re a detection engineer and have to write Yara rules to detect malware, Kesakode can be rather handy too! The hard part in writing a good Yara rule is finding portions of code and strings which are unique to the malware. Kesakode can help you there, even if we don’t have the malware in our database!
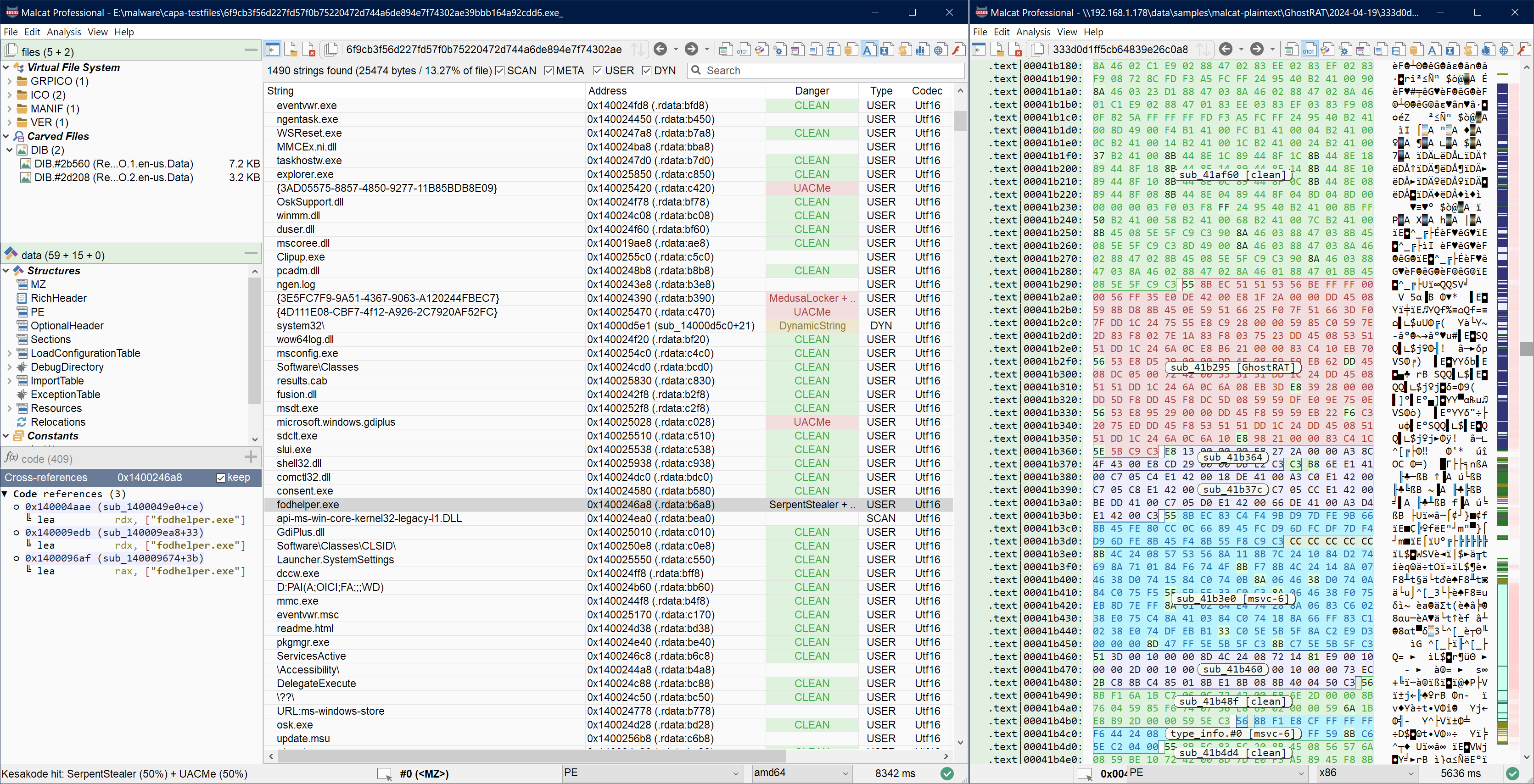
Data and strings coloring in Malcat after a kesakode request
By displaying UNKNOWN and MALICIOUS functions/strings inside the Kesakode lookup view, you’ll be able to spot artifacts that have never been seen in any library/clean program. These make very good candidates for your new Yara rules. The coloring scheme (LIBRARY, MALICIOUS and CLEAN labels) is also applied to Malcat’s Strings list, Hexadecimal view, Structure/text view and Disassembly view if you prefer to build your Yara rule from there. Combined with Malcat’s Yara editor / browser, this makes writing detection rules easier.
Faster reverse engineering
Even if malware are not your cup of tee and you just want to reverse engineer a standard application, Kesakode can help you identify low-value functions in your program. Indeed, chances are that you’ll want to focus your efforts on the portions of code that are unique to your program: complex algorithms, unique strings, etc.
Color helpers in disassembly view after a kesakode request
After every Kesakode database lookup, the Disassembly view in Malcat will label/color every known function found in either CLEAN programs or LIBRARY (with the name of the library). This can speedup the reversing process a lot: just ignore the boring part and focus on the unique parts of your program!
External Kesakode providers
Kesakode is a service offered to owners of Full & Pro versions of Malcat. But maybe you already had access to similar services, for instance via an Intezer subscription. Or maybe you would like to use your own self-hosted function and string identification service.
Starting with version 0.9.9, it is possible to use alternative sources for Kesakode requests. By Writing your own threat intelligence provider, you can implement your own OnlineChecker.kesakode() method. Malcat will automatically detect these new sources of intel and offer you to select them in the Kesakode lookup view.
Warning
While Malcat’s Kesakode only submits hashes for identification, third-party providers may function differently. These providers have access to the whole analysis and file objects, they may upload the whole file for analysis. Keep it in minde if privacy is of value to you.
Kesakode frequently asked questions
- Where does the name “Kesakode” comes from?
The word Kesakode is a combination of Kesako (from the occitan qu’es aquò, meaning what is it?) and the word code, so basically: What is this code?
- How can I use this service? How much does it cost?
This service comes for free with any Full & Pro versions. You can access it within Malcat’s Kesakode lookup view. Note that you’ll need a running license of Malcat for online queries, i.e you must be within the 1 year update period. See below for questions regarding your monthly quota.
- How many queries can I make?
There are two limits built for online Kesakode queries. The first limit is in the Web server, which will block you if you make more than 60 queries / hour. Note that you should not reach this limit under normal usage.
The second limit is your montly quota. This makes sure things stay civilized and every user has access to the service. Currently, the service is in beta-test and we want to put the server under stress. Your monthly quota is thus currently 160 requests / month for full users and 320 queries / month for pro users.
Depending on the result of the stress test, we’ll set a more reasonable quota in the future, most likely 40 requests for full users and 80 for pro users. But this is not written in stone and will depend on actual usage of the service.
- Kesakode is great, but I need more quota!
We are happy that you like the new detection service. If you need more quota, we can always setup a server just for you. Note that this requires some effort, time and money. The easiest way is to just Contact us and we will work something out.
- Kesakode sucks, it can’t identify my malware!
Nowadays, 99% of the malware found in the wild are packed/obfuscated. Kesakode, works only on unpacked/plain-text malware. To unpack your malware, there are many solutions. The simplest one is to download dumps issued by the Triage sandbox or AnyRun, chances are your unpacked malware is in one of them.
If you are indeed analysing a plain-text malware, then maybe we just don’t have it in our database, it happens. You can always share the sample with us and we will make sure it gets detected in the next indexation. For more details about false positive/false negatives, see Submitting false positives/negatives.
- How does it compare against Intezer, Threatray, Glimps or other similar services?
Kesakode tries to achieve the same objective as all these solutions, that is: identify malware families and known artifacts in programs. But there are of course differences.
On the plus side, Kesakode is relatively fast. It also tries to identify malware on three different levels (code, strings and immediates/constants). As far as we know it’s the only solution to do that.
On the minus side, most of the aforementioned solutions offer more: a bigger & better dataset, threat-intelligence capabilities (i.e explore their online sample database) and most of the time they also have a small sandbox to try to unpack the sample for you. .
Note that I only have incomplete information on these solutions, as I don’t have the budget to afford any of them. So take these points with a grain of salt. The best way to compare things is always to do your own test!
- Can I include it in my malware analysis pipeline?
Yes! Thanks to Malcat’s GUI-less python module (see Run Malcat from your python interpreter), you can already analyse files directly from your python program. The python bindings allow you to programmatically query the online Kesakode service. You can also perform offline Kesakode scans for better performances, but this features requires an OEM license for Malcat: don’t hesitate to Contact us.
- Why can’t I read the word AI anywhere?
There are problematic where AI is not well suited, and in our opinion this is one of them. The dataset on the malware side is small (a few thousands families is considered small for machine learning), but is very large on the clean side: this is far from ideal for proper machine learning.
Additionally, ML/DL models are prone to false positives, which is particularly dangerous when doing malware attribution. We believe that a good algorithm and solid optimisation will take your farther, but don’t take our word for it and see for yourself!