File parsers
Malcat makes use of the 50+ files parsers in order to identify the type of current file and highlight all of its internal structures. The file parsers also are used to carve known file type from the current file at any location (e.g. embedded archives or images inside a PE file).
How parsing is done
All of Malcat parsers are written in python. Relying on python allows Malcat to reduce the attack surface for bad parsing (file formats are tricky) and significantly speeds up the development of new file parsers (you can test everything live, just hit Ctrl+R ). This comes with a small performance penalty of course, but in practice it is negligible, provided some basic guidelines are followed.
All parsers are located in data/filetypes or in the filetypes sub-directory of your User data directory. When a new file needs to be analyzed in Malcat, the file parser is the first to be called. It will be responsible for several things:
Identify all of the file’s structures (the ones you can see in the Structure/text view)
Describe the file’s section mapping if relevant
Collect any metadata (date of creation, authors, etc.)
List all Virtual files if applicable (e.g. for an archive)
Populate the initial Symbols list if any (e.g. with imports and exports for a PE file)
Once done, the Analysis engine can work its magic and start the analysis of the file.
File carving
File parsers are also used in Malcat’s carving algorithm in order to detect any file embedded inside the currently analyzed file. This feature is not only useful for DFIR (e.g. when analysing memory dumps), but also for malware analysis, when malware embed their next-stage payload inside a data section for instance.
All parsers located in data/filetypes (or in your User data directory)will be used in the carving process. Every time that the magic regexp of a parser matches, the parser’s FileTypeAnalyzer.parse() method will be called. During file carving, the whole parsing process of the parser won’t need to happen. In this mode, the parser may perform an early exit (for performance reasons) if both following conditions are met:
The parser did confirm the file type by calling the
malcat.FileParser.confirm()methodThe parser did specify the end of file by calling the
malcat.FileParser.set_eof()method
The list of carved file is reported inside the Carved files tab in the UI.
Supported file formats
Malcat focuses mainly on file formats used directly or indirectly by malware authors. Adding a new file type is easy. Please refer to Writing new parsers. If you wish to make your new file format official, please refer to Contributing.
Programs
Here you can find the current list of supported executable formats:
Name |
Structure parsing |
Debug infos |
Resources |
Notes |
|---|---|---|---|---|
AutoIT |
3.26+ only |
Scripts can be decompiled using F4 |
||
COFF |
Yes |
symbols and cv13 |
relocations, symbols, imports |
|
ELF |
Yes |
symbols, no DWARF |
relocations, symbols, imports, big and little endian |
|
ELF::Golang |
Yes |
pcln + file tables |
||
InnoSetup |
Yes |
Yes |
setup script can be disassembled |
|
LNK |
Yes |
while not a program format per se, it can be used to run commands |
||
MACHO |
Yes |
symbols, no DWARF |
relocations, symbols, imports, big and little endian |
|
MACHO::Golang |
Yes |
pcln + file tables |
||
MDMP |
Yes |
Yes |
Windows minidumps, partial and full dumps supported |
|
NSIS |
Yes |
Yes |
setup script can be disassembled, most sections parsed |
|
OLE |
Yes |
VBA macros can be displayed using F4 |
||
PE/PE+ |
Yes |
debug dir, no PDB |
Yes |
exports, imports (+ bound/delay), relocations, tls, debug, load config, certificates, version informations |
PE::DotNet |
Yes |
Yes |
Yes |
types, methods, resources, exceptions, strings |
PE::Golang |
Yes |
pcln + file tables |
||
PE::VB |
Yes |
types and events |
VB forms |
native and PCode support, project infos, objects array, forms and events |
PYC |
Yes |
Yes |
support for python 2.7+ and 3.6+, can handle PY2EXE and PYINST scripts |
|
VBE |
Yes |
Malcat supports unpacking the original VBS script |
||
XLS |
Yes |
The /Workbook stream inside OLE containers. Cell informations (including formulas) can be recovered using F4 |
||
XLSB |
Yes |
The .bin files inside OpenXML .xlsb containers. Cell informations (including formulas) can be recovered using F4 |
- Structures parsing:
if the file format parser identifies (most of) the binary structures of the file format
- Debug informations:
if debug informations are parsed
- Resources:
if the program embeds resource, can Malcat identify and extract them?
Archives / file systems / databases
While Malcat has no pretension of being a full-fledged archive opener, it supports most archive types used by malware. Some file format parsers are more advanced than others and even allow the user to open archive member directly inside Malcat. Here is a list of supported file formats:
Name |
Structure parsing |
In-app unpacking |
Summary |
Notes |
|---|---|---|---|---|
7Z |
EncodedHeader only |
No |
No |
|
ACE |
Yes |
Yes |
Yes |
|
ACEDB |
Yes |
Yes |
Yes |
Access Database, can parse some tables and file attachements |
AR |
Yes |
Yes |
Yes |
Used in static libraries (.lib, .a) |
ASAR |
Yes |
Yes |
Yes |
Archive format used by Electron apps |
AutoIt |
3.26+ only |
3.26+ only |
Yes |
Scripts can be decompiled using F4 |
CAB |
Yes |
zlib encoding only |
Yes |
|
CFB/OLE2 |
Yes |
Yes |
Yes |
VBA macros can be displayed using F4 |
FAT12/16/32 |
Yes |
Yes |
Yes |
Currently limited to small to medium files trees |
GZIP |
Yes |
Yes |
Yes |
|
InnoSetup |
Yes |
Yes |
Yes |
Support from InnoSetup 4.1.0 up to 6.7.1 |
ISO |
Yes |
Yes |
Yes |
No Juliet/RockRidge extensions support |
JFFS2 |
Yes |
lzo/lzma/rtime/zlib only |
Yes |
|
MSI |
Yes |
Yes |
Yes |
MSI tables can be displayed using F4 |
NSIS |
Yes |
zlib and lzma, no bz2 |
Yes |
|
PYINST |
Yes |
Yes |
Yes |
Extracted python scripts get their python header restored |
PICKLE |
Yes |
N/A |
No |
Disassembler available |
PYZ |
Yes |
Yes |
Yes |
Extracted python scripts get their python header restored |
RAR4 |
Yes |
Yes |
Yes |
Archives comments are shown for easy SFX analysis |
RAR5 |
Yes |
Yes |
Yes |
Archives comments are shown for easy SFX analysis |
SquashFS |
Yes |
lzo/lzma/xz only |
Yes |
Can also display meta streams |
Sqlite |
Partial |
Not yet |
No |
Work in progress |
TAR |
Yes |
Yes |
Yes |
|
UDF |
Yes |
Yes |
Yes |
|
UImage |
Yes |
lzo/lzma/gzip/bzip2 only |
Yes |
|
UPX |
Yes |
UPX stream version 10+ |
Yes |
For PE and ELF files only |
U-MACHO |
Yes |
Yes |
Yes |
Universal MACH-O container |
VHD |
Yes |
Yes |
Yes |
Support for dynamic disks |
ZIP |
Yes |
Yes |
Yes |
|
ZLIB stream |
Yes |
Yes |
Yes |
- Structures parsing:
if the file format parser identifies (most of) the binary structures of the file format
- In-application unpacking:
if the file format parser can directly extract and open archive members. Inside Malcat, one can then open a file by double-clicking them inside the Virtual File System tab.
- Summary:
if Malcat displays a summary report in the Summary view
Multimedia / documents
Document/pictures identification is very useful for malware analysis. A lot of obfuscators love to disguise their payloads as multimedia files. Or hide it inside a multimedia file, in some unused space.
Name |
Structure parsing |
Metadata |
Notes |
|---|---|---|---|
BMP |
Yes |
Both BMP and DIB (i.e BMP without FileHeader) are supported |
|
DOC |
Partial (FCB) |
Yes |
The /WordDocument stream inside OLE containers |
EMF |
Yes |
Yes |
Used in office documents |
GGUF |
Yes |
Yes |
Format used to distribute LLMs |
GIF |
Yes |
Yes |
|
ICO |
Yes |
||
JPEG |
Yes |
Tiff |
|
ONE |
Yes |
No |
Microsoft OneNote files. You can list and open embedded file objects |
OOXML |
No |
No |
Well it’s a ZIP, so you can browse it inside Malcat |
Minimal |
No |
Very minimal support since not really a binary format |
|
PNG |
Yes |
Yes |
Pixel information can be extracted using scripts |
WAV |
Basic |
No |
|
XLS |
Yes |
Yes |
Cell content + formula can be displayed using F4 |
XLSB |
Yes |
Yes |
Cell content + formula can be displayed using F4 |
- Structures parsing:
if the file format parser identifies (most of) the binary structures of the file format
- Metadata:
if most metadata (author, comments, time, etc.) are extracted
Writing new parsers
Adding a new file parser in Malcat is just the matter of adding a new python file in the filetypes sub-directory of your User data directory and creating a class which inherits from FileTypeAnalyzer. Your parser class should define at least the following items:
a class attribute
name: a (unique) short identifier/name for the file type, e.g. “PE” or “ISO” (seeFileTypeAnalyzer.name)a class attribute
regexp: a regular expression using pcre2 syntax which has to match somewhere in the file for your parser to be even called (seeFileTypeAnalyzer.regexp)a class attribute
category: the category of the file type. This tells malcat which icon to use to represent the file (seeFileTypeAnalyzer.category)a method
parse, which will be called by Malcat and will do all the validating/parsing of the file (cf.FileTypeAnalyzer.parse())
If you want to test your parser, no need to restart Malcat: just hit Ctrl+R and it will be reloaded and reapplied to the current file (if the regexp matches). As an example, we can have a look at the PNG parser located at data/filetypes/PNG.py:
from filetypes.base import *
import malcat
class PNGAnalyzer(FileTypeAnalyzer):
category = malcat.FileType.IMAGE
name = "PNG"
regexp = r"\x89PNG\r\n\x1A\n"
def parse(self, hint=""):
yield Bytes(8, name="Signature", category=Type.HEADER)
# ...
Note
By defaults, the parsing starts at the location where the magic regexp was found. If the magic regexp is not the start of the file, please see Custom parsing start and context.
Now all you have to do is to write the parse method. The parse method will be responsible for :
Parsing/identifying all of the file’s structures (the ones you can see in the Structure/text view)
Describing the file layout
Collect any metadata (date of creation, authors, etc.)
Listing all Virtual files (e.g. for an archive)
Populating the initial Symbols list if any (e.g. with imports and exports for a PE file)
Identifying at least one field/structure is mandatory. The rest is optional and may or may not be relevant depending on the file type you are parsing. If during parsing you notice that this is not a valid file (e.g. the magic regexp hit was a false positive), you can abort the parsing at any time by raising a FatalError (cf. Exceptions and error handling). Each item will be discussed below.
Note
While these tutorial should be the first documentation you read when writing your own parser, we encorage you to also have a look at all the existing file parsers located in data/filetypes.
Parsing
The main goal of the parser is to identify known structures/fields inside the parsed file. This is done from within the FileTypeAnalyzer.parse() method by using the python keyword yield. A typical parser will FileTypeAnalyzer.jump() to various offsets in the file and yield a description of the different fields which are located there. Fields are named objects (the names you see in the Structure/text view for instance) and can be:
an atomic field : an integer, a string, a timestamp, etc
a structure field : like a typical C structure, a sequence of named fields
an array field : like a typical C array, a sequence of identical (unnamed) fields
a bitfield : a sequence of Bit fields
Whenever you yield a field/array/bitfield/structure from you parser, you will get the value of the field back, which will be:
the corresponding python value for atomic fields, e.g. a
datetime.datetimeforTimestampfields, astrforStringUtf8fields or aintforUInt64fields.a
malcat.FieldAccessinstance for structures, arrays and bitfields. Themalcat.FieldAccessobject allows you to navigate into these aggregate fields in a pythonic way. The interface is the same as for the well-documentedmalcat.StructAccessobject described in details in the scripting documentation.
Yielding a field/structure also moves the field/parsing pointer at the end of the field/structure, so that the next yield will be located right after the previous field/structure. Let us have a look at the start of the PE parser for instance:
class MZ(Struct):
def parse(self):
#...
class PE(Struct):
def parse(self):
#...
def parse(self, hint=""):
mzheader = yield MZ(category=Type.HEADER)
# you can also access the structure by name after it has been yielded: mzheader = self["MZ"]
self.jump(mzheader["AddressOfPE"]) # jump to PE header offset
pe = yield PE(category=Type.HEADER) # yield pe header structure
magic, = struct.unpack("<H", self.look_ahead(2))
self.is64 = magic == 0x020B
if self.is64:
optheader = yield OptionalHeader64(name="OptionalHeader", category=Type.HEADER) # located right after the PE struct
self.set_architecture(malcat.Architecture.X64)
else:
optheader = yield OptionalHeader32(name="OptionalHeader", category=Type.HEADER) # located right after the PE struct
self.set_architecture(malcat.Architecture.X86)
self.set_imagebase(optheader["ImageBase"])
You can see there the use of FileTypeAnalyzer.jump() and the yield keyword to identify three structures. The script also uses the function malcat.FileTypeAnalyzer.look_ahead() to read the content of the file at the location pointed by the field pointer. Please note that field/structure cannot overlap (this would throw an exception) and a field/structure cannot be located past the end of the file.
You will also notice that all field types accepts (at least) the following keyword arguments:
name: the name of the field, that will be displayed in the Structure/text view
comment: a comment describing the field (optional). This will be displayed in the Structure/text view when the user hovers the field
parent: there you can give an already parsed
malcat.FieldAccessinstance which should be considered as the parent of the yielded field (optional). This will make the currently yield field appear as a child of the parent field in the data tab. This is purely visual and just there to help sort out all the structures of the file:

Use of the parent keyword argument in fields
Additionally, for level-0 fields/structures, you may specify a category keyword argument that will tell Malcat which category to put the structure in. This will also help users to fine-tune the Highlighting. The category can be one of:
Type.HEADER: For structures/fields used to describe the file format
Type.CODE: For structures/fields containing executable code
Type.DATA: For structures/fields containing arbitrary/user-defined data
Type.DEBUG: For structures/fields containing debug information
Type.METADATA: For structures/fields containing metadata information (comments, times, etc)
Type.FIXUP: For structures/fields containing fixup information
Type.RESOURCE: For structures/fields containing images, sounds, etc data
That’s it for the basic of parsing. Since parsers are python classes, you may use whatever python code you need in addition to the methods defined in the malcat.FileTypeAnalyzer class, which makes them pretty flexible. The only thing you need to know now are the different fields that can be yielded, which will be described below.
Note
If you prefer to look at code, all the available types are defined in <malcat install dir>/bindings/filetypes/types.py.
Numeric types
Numeric fields describe a numerical value. They are non-aggregate data types that you may yield either from the FileTypeAnalyzer.parse() method or from the Struct.parse() method. The most important ones are listed below, but you can get the complete list by looking at bindings/filetypes/types.py.
The value returned when yielding an integer field is either an int or a float. Like most fields, they accept a name and comment keyword argument. Integer also accept a *values* parameter for enums. The values parameter is simply a list of tuple (enum name, enum value) which describes all the possibles values that the field can take. In the Structure/text view, they would appear as enums and can be edited via a combobox. A small example taken from data/filetypes/ACE.py:
class UnknownHeader(Struct):
def parse(self):
yield UInt16(name="Crc", comment="crc of data")
size = yield UInt16(name="Size", comment="size of data")
yield UInt8(name="Type", values=[
( "MAIN", 0),
( "FILE32", 1),
( "RECOVERY32", 2),
( "FILE64", 3),
( "RECOVERY64A", 4),
( "RECOVERY64B", 5),
])
Class |
Size |
Equivalent C type |
Python type |
Parameters |
Description |
|---|---|---|---|---|---|
UInt8 |
1 |
uint8_t |
int |
name, comment, values |
A byte |
Int8 |
1 |
int8_t |
int |
name, comment, values |
A signed byte |
UInt16 |
2 |
uint16_t |
int |
name, comment, values |
A word |
Int16 |
2 |
int16_t |
int |
name, comment, values |
A signed word |
UInt16BE |
2 |
int |
name, comment, values |
A word, big endian |
|
Int16BE |
2 |
int |
name, comment, values |
A signed word, big endian |
|
UInt24 |
3 |
int |
name, values |
A 3-bytes int |
|
Int24 |
3 |
int |
name, values |
A signed 3-bytes int |
|
UInt24BE |
3 |
int |
name, values |
A 3-bytes int, big endian |
|
Int24BE |
3 |
int |
name, values |
A signed 3-bytes int, big endian |
|
UInt32 |
4 |
uint32_t |
int |
name, comment, values |
A dword |
Int32 |
4 |
int32_t |
int |
name, comment, values |
A signed dword |
UInt32BE |
4 |
int |
name, comment, values |
A dword, big endian |
|
Int32BE |
4 |
int |
name, comment, values |
A signed dword, big endian |
|
UInt48 |
6 |
int |
name, values |
A 6-bytes int |
|
Int48 |
6 |
int |
name, values |
A signed 6-bytes int |
|
UInt48BE |
6 |
int |
name, values |
A 6-bytes int, big endian |
|
Int48BE |
6 |
int |
name, values |
A signed 6-bytes int, big endian |
|
UInt64 |
8 |
uint64_t |
int |
name, comment, values |
A qword |
Int64 |
8 |
int64_t |
int |
name, comment, values |
A signed qword |
UInt64BE |
8 |
int |
name, comment, values |
A qword, big endian |
|
Int64BE |
8 |
int |
name, comment, values |
A signed qword, big endian |
|
PrefixedVarUInt64 |
1-9 |
int |
name, comment, values |
variable uint64 where first byte tells how many bytes there are (always big-endian) |
|
VarUInt64 |
1-10 |
int |
name, comment, values |
variable uint64 where first bit (0x80) of every byte tells if there is more data to come |
|
VarUInt64BE |
1-10 |
int |
name, comment, values |
variable uint64 where first bit (0x80) of every byte tells if there is more data to come, big endian |
|
Float |
4 |
float |
float |
name, comment |
A 32bits float |
FloatBE |
4 |
float |
name, comment |
A 32bits float, big endian |
|
Double |
8 |
double |
float |
name, comment |
A 64 bits double-precision float |
DoubleBE |
8 |
float |
name, comment |
A 64 bits double-precision float, big endian |
Strings
Strings are fields which contain character data. The value returned when yielding a string field is either a str or a malcat.FieldAccess for strings composed of a size and the string data. Like most fields, they accept a name and comment keyword argument. There are three types of strings:
fixed-size strings (the
String*fields) whose size is known in advancenull-terminated dynamic-size strings (
CString*) whose size will be infered by Malcat by reading the file contentprefixed strings (
Pascal*,UnicodeString) which are actually structures with two fields: a Size field, and a String field:
Class |
Size |
Equivalent C type |
Python type |
Parameters |
Description |
|---|---|---|---|---|---|
String |
N |
char[] |
str |
N, name, comment, zero_terminated |
A fixed-size ascii string |
StringUtf8 |
N |
char[] |
str |
N, name, comment, zero_terminated |
A fixed-size UTF8 string |
StringUtf16le |
N |
char16[] |
str |
N, name, comment, zero_terminated |
A fixed-size UTF16-le string |
StringUtf16be |
N |
char16[] |
str |
N, name, comment, zero_terminated |
A fixed-size UTF16-le string |
CString |
? |
char* |
str |
name, comment, max_size=512 |
A null-terminated Ascii string, Malcat will truncate the string if bigger than max_size bytes |
CStringUtf8 |
? |
char* |
str |
name, comment, max_size=512 |
A null-terminated UTF8 string, Malcat will truncate the string if bigger than max_size bytes |
CStringUtf16le |
? |
char16* |
str |
name, comment, max_size=512 |
A null-terminated UTF16-le string, Malcat will truncate the string if bigger than max_size bytes |
CStringUtf16be |
? |
char16* |
str |
name, comment, max_size=512 |
A null-terminated UTF16-be string, Malcat will truncate the string if bigger than max_size bytes |
PascalString |
Prefixed |
name, comment |
A struture composed of the size of the string (dword), followed by the actual Ascii string |
||
PascalString8 |
Prefixed |
name, comment |
A struture composed of the size of the string (byte), followed by the actual Ascii string |
||
UnicodeString |
Prefixed |
UNICODE_STRING |
name, comment |
A struture composed of the size of the string (dword), followed by the actual UTF16-le string |
Time
Times and dates can be expressed in various different formats. The following field types can be used.
Strings are fields which contain character data. The value returned when yielding a string field is a datetime.datetime instance. Like most fields, they accept a name and comment keyword argument.
Class |
Size |
Equivalent C type |
Python type |
Parameters |
Description |
|---|---|---|---|---|---|
Filetime |
8 |
FILETIME |
datetime.datetime |
name, comment |
Time format used in Windows |
Timestamp |
4 |
time_t |
datetime.datetime |
name, comment |
Unix timestamp |
TimestampBE |
4 |
datetime.datetime |
name, comment |
Unix timestamp, big endian |
|
Timestamp2000 |
4 |
datetime.datetime |
name, comment |
Like a Unix timestamp, but base date is 2000-01-01 |
|
DosDateTime |
4 |
datetime.datetime |
name, comment |
Date-time format used in DOS |
|
DosDate |
2 |
datetime.date |
name, comment |
Date format used in DOS |
|
DosTime |
2 |
datetime.time |
name, comment |
Time format used in DOS |
Pointers
Malcat also has support for pointer fields. These are numerical fields which points toward a data. These are displayed as clickable fields in the Structure/text view. The value returned when yielding a string field is a int. Like most fields, they accept a name and comment keyword argument, but they also accept two additions args:
hint: the Field type at the end of the pointer. Malcat may use the information to displayed the pointee field (espeicially for strings)
zero_is_invalid: if True, a value of zero is considered to be invalid, and the pointer will be displayed in the dim color inside the Structure/text view
base: only for
Offset*instances: the offset is actually a delta offset relative to this base offset
Class |
Size |
Equivalent C type |
Python type |
Parameters |
Description |
|---|---|---|---|---|---|
Offset16 |
2 |
uint16_t |
int |
name, comment, hint, zero_is_invalid, base |
A 16 bits file offset |
Offset32 |
4 |
uint32_t |
int |
name, comment, hint, zero_is_invalid, base |
A 32 bits file offset |
Offset32BE |
4 |
int |
name, comment, hint, zero_is_invalid, base |
A 32 bits file offset, big endian |
|
Offset64 |
8 |
uint64_t |
int |
name, comment, hint, zero_is_invalid, base |
A 64 bits file offset |
Offset64BE |
8 |
int |
name, comment, hint, zero_is_invalid, base |
A 64 bits file offset, big endian |
|
Rva |
4 |
uint32_t |
int |
name, comment, hint, zero_is_invalid |
A relative virtual address, aka a 32-bits displacement relative to |
Va32 |
4 |
uint32_t |
int |
name, comment, hint, zero_is_invalid |
A 32bits memory address |
Va32BE |
4 |
int |
name, comment, hint, zero_is_invalid |
A 32bits memory address, big endian |
|
Va64 |
4 |
uint64_t |
int |
name, comment, hint, zero_is_invalid |
A 64bits memory address |
Va64BE |
4 |
int |
name, comment, hint, zero_is_invalid |
A 64bits memory address, big endian |
Other
Here are a few additional non-aggregate field types which do not really fit in other categories:
Class |
Size |
Equivalent C type |
Python type |
Parameters |
Description |
|---|---|---|---|---|---|
GUID |
16 |
str |
name, comment, microsoft_order |
A 16-bytes GUID field. The yielded python value is the string representation of the GUID, e.g. |
|
Bytes |
N |
uint8_t[] |
bytes |
N, name, comment |
N raw bytes |
Unused |
N |
void* |
bytes |
N, name, comment |
N unused/reserved/padding bytes, will be displayed in a dimmed color |
Align |
depends |
None |
N, name, comment |
|
|
StructAlign |
depends |
None |
N, name, comment |
|
Structures/records
Structures (aka records) are aggregate fields, meaning they are composed of one ore more adjacent sub-fields. They are more expressive than C-style structures though, as every types.Struct has its own parse() method.
Contrary to atomic fields, there are very little predefined structure fields in Malcat: you’ll likely have to define your own. To define a new structure, it is very simple though:
Create a python class inheriting from
types.StructDefine a
parse(self)method in the structure, which works like theFileTypeAnalyzer.parse()method we have seen before (except that you cannotFileTypeAnalyzer.jump()around since structure fields need to be adjacent)
Note
If you define your structure at the global scope of your parser python file (and if their types.Struct.parse() method does not need to access the types.Struct.parser attribute), it will be available to the user as “python type” in the Apply a custom type dialog. Try it out!
For instance, have a look at the following extract of the structure OptionalHeader32’s parse method:
class OptionalHeader32(Struct):
def parse(self):
magic = yield UInt16(name="Magic", comment="magic", values=[
("PE32", 0x10b),
("ROM", 0x107),
("PE32+", 0x20b),
])
if magic != 0x010B and magic != 0x0107:
raise FatalError("Invalid magic value: {:x}".format(magic))
yield UInt8(name="MajorLinkerVersion", comment="linker version (major)")
yield UInt8(name="MinorLinkerVersion", comment="linker version (minor)")
# ...
Once this structure has been defined, it can be used and yielded like any other field type, e.g.:
optheader = yield OptionalHeader32(name="OptionalHeader", category=Type.HEADER)
linker_version = "{}.{}".format(optheader["MajorLinkerVersion"], optheader["MinorLinkerVersion"])
The value you get back from yielding a structure is a malcat.FieldAccess instance which allows you to access the structure and its fields easily. And that’s it! To help you further, Structure objects also defines a couple of attributes/methods that you may access from within your overridden types.Struct.parse() method:
- class types.Struct
This class is the base class of custom structure fields.
- parser: malcat.FileTypeAnalyzer
a pointer to the current file type parser. Note that this field can only be accessed during the file parsing process, i.e. from within the
parse()method.
- parse()
You will have to override this method with your parse code
- look_ahead(size=1)
Read file data at the current parsing offset. Equivalent to
self.parser.read(self.parser.tell(), size). Note that this method can only be called during the file parsing process, i.e. from within theparse()method.- Parameters:
size (int) – how many bytes to read
- Return type:
bytes
Arrays
Arrays are aggregate fields too, like structures, with the difference that all their sub-fields have the same type. Malcat supports three types of arrays, depending on whether the array size is known or not, or if the cell type need parsing or not. The three types of array fields will be discussed below:
Class |
Size |
Equivalent C type |
Python type |
Parameters |
Description |
|---|---|---|---|---|---|
Array |
N |
Field[N] |
N, Field, name, comment |
A fixed-size array of N elements of type T. Only the first cell is parsed, all other cells are assumed to have the same size |
|
DynamicArray |
? |
Field[?] |
fn_terminator, N, Field, name, comment |
An array, but the size of the array is given by the predicate: fn_terminator(cell) == True. Only the first cell is parsed, all other cells are assumed to have the same size |
|
VariableArray |
N |
N, FieldClass, name, comment |
An array, but its elements can have different sizes. In practice, this is a structure with N fields, and each field will be parsed. Note that you need to give the field class as parameter for this one. |
The simplest array type you can use is the Array field. This is the one you should use when the size of the array is known and all cells are identical. The first two parameters you should give the Array constructor are:
The number of cells in the array
The field type of the cells
Note
If the array cell type is a structure, the parse method will only be called for the first cell of the array, and Malcat will assume that all subsequent cells have the exact same size. This allows for efficient parsing for even large arrays. If your array cells may have varying size, you should use VariableArray instead.
A simple example, taken from the PE parser:
expdir = yield ExportDirectory(name="ExportDirectory", category=Type.HEADER)
# ...
if nametable_off:
self.jump(nametable_off)
names = yield Array(expdir["NameTableEntries"], Rva(hint=String(0, True)), name="ExportNameTable", category=Type.HEADER, parent=expdir)
if ordinaltable_off:
self.jump(ordinaltable_off)
ordinals = yield Array(expdir["NameTableEntries"], UInt16(), name="OrdinalNameTable", category=Type.HEADER, parent=expdir)
if addresstable_off:
self.jump(addresstable_off)
addresses = yield Array(expdir["AddressTableEntries"], Rva(), name="ExportAddressTable", category=Type.HEADER, parent=expdir)
Sometimes, you don’t know what will be the size of the array. In this case, the array is usually terminated with a special terminator cell. In this case, you can use the DynamicArray field type. In this array type, the first constructor argument of the array is not the size, but a python function that returns True when the last cell (aka terminator cell) is reached. The size of this array type is always at least 1.
Note
While all cells still need to have the same size, using a DynamicArray is a bit less performant than the previous Array type since all cells need to be evaluated by the fn_terminator function.
An example is given below:
def parse_debug(self, dbg_foff, dbg_size):
self.jump(dbg_foff)
def is_last_debug_entry(current_cell, current_array_size):
if current_cell.offset + current_cell.size >= dbg_foff + dbg_size:
return True
if current_cell["PointerToRawData"] == 0:
return True
if current_array_size > 1024:
return True # avoid parsing most-likely invalid debug directories
return False
dds = yield DynamicArray(is_last_debug_entry, DebugDirectoryEntry(), name="DebugDirectories", category=Type.DEBUG)
Finally, the last array type that you can use is the VariableArray. This array type supports cells of different size. It means that if your cell type is a structure, every cell’s types.Struct.parse() method will be called. Basically, this is array is just a structure with N unamed fields. You can see in the example below that the structure PascalVariable does not have a fixed size: the last field (ExportName) is only present iff the structure’s flag Exported is set. As a consequence, you have to use a VariableArray if you want to yield an array of this cell type, since cell sizes may vary:
class PascalVariable(Struct):
def parse(self):
yield UInt32(name="TypeIndex")
flags = yield BitsField(
Bit(name="Exported", comment="Variable is exported"),
name="Flags", comment="variable characteristics")
if flags["Exported"]:
yield PascalString(name="ExportName")
vars = yield VariableArray(varcount, PascalVariable, name="VariablesArray")
# you get a malcat.FieldAccess back
for var in vars:
print(var["TypeIndex"])
Note
For this array type, you should give as parameter the class of the cell type to use, and not an instance!
Bitsfields
The last aggregate field type that you can use in your parser is the BitsField type. Bits fields are arrays of single bits with a few twists:
Each bit has a name
Number of bits has to be a multiple of 8 (if it is not, Malcat will round it up to the next multiple of 8)
Bits are defined from bit 0 to bit n
The constructor for the Bitsfield type is also a bit different. In addition to the usual name and comment keyword parameters, it takes all the Bit() fields (always from the bit 0 to the bit n) composing the bits field as standard arguments. If one or more bits are not used, which happens a lot in specifications, you can use the special field Nullbits(<number of unspecified bits>) in your bits list. Here is an example take from the PE parser:
process_heap_flags = yield BitsField(
Bit(name="HEAP_NO_SERIALIZE", comment="serialized access will not be used for this allocation"),
NullBits(1),
Bit(name="HEAP_GENERATE_EXCEPTIONS", comment="system will raise an exception to indicate a function failure, such as an out-of-memory condition, instead of returning NULL"),
Bit(name="HEAP_ZERO_MEMORY", comment="allocated memory will be initialized to zero"),
NullBits(14),
Bit(name="HEAP_CREATE_ENABLE_EXECUTE", comment="blocks that are allocated from this heap allow code execution"),
NullBits(13),
lsb=True,
name="ProcessHeapFlags", comment="heap flags that correspond to the first argument of the HeapCreate function.")
# you get a malcat.FieldAccess back
if process_heap_flags["HEAP_NO_SERIALIZE"]:
# ...
This code will produce the following field view in the Structure/text view:

A Bitsfield
And that’s it. Bitsfields also accept an optional lsb keyword parameter, which is True by default. It tells Malcat how the bytes are stored in the bitvector. For instance with lsb set, the bit 0x8000 is stored in the second byte. If lsb is not set, in the first byte (assuming the bitsfield has 16 bits).
Note that when you yield bitfields, you also get a malcat.FieldAccess instance back that lets you access individual bits easily.
Exceptions and error handling
Parsers in Malcat are responsible for both parsing and validating their file type.
Any exception thrown before the malcat.FileParser.confirm() method has been called will abort the whole parsing all-together and the file won’t be considered of being of the parser’s supported type. Once malcat.FileParser.confirm() has been called from within the parser though, the file type will be set for good, and any subsequent exception will simply be reported in the analysis’s log (you can see the log in the Console window).
Now that’s all nice and good, but which type of exceptions are available to your parser? Malcat defines the base type ParsingError, which is the only type of exception which can be safely thrown from your parser.
Warning
Any exception not inheriting from ParsingError risen from your parser will be considered as a bug by Malcat: the exception will be displayed in red in the Console window and the analysis will be considered as unsuccessful. Please handle all the edge cases properly in your parsing code.
Inheriting from the class ParsingError are 4 additional exceptions that you may use and/or encounter:
- FatalError(ParsingError):
You should raise a
FatalErrorexception when you encounter invalid data or structure not respecting the specifications and want to abort the parsing.- OutOfBoundError(ParsingError):
This exception will be risen by Malcat if you try to:
Read outside of the file boundaries using any of the
read_*methodsYield a structure outside of the file boundaries
- SuperposingError(ParsingError):
This exception will be risen by Malcat if you yield a structure/a field and this structure/field overlaps an already-defined structure/field
- InvalidPassword(ParsingError):
You can raise this error from an unpack method to notify the user that the file requires a different password to be open (cf. The Virtual File System).
You can of course define your own parsing exceptions, just make sure it inherits from ParsingError.
File layout / regions
Another responsibility of the parser is reconstructing the layout of the analysed file. It means slicing the file into different regions with a meaningful name and permissions. In the Summary view, the layout is displayed visually:
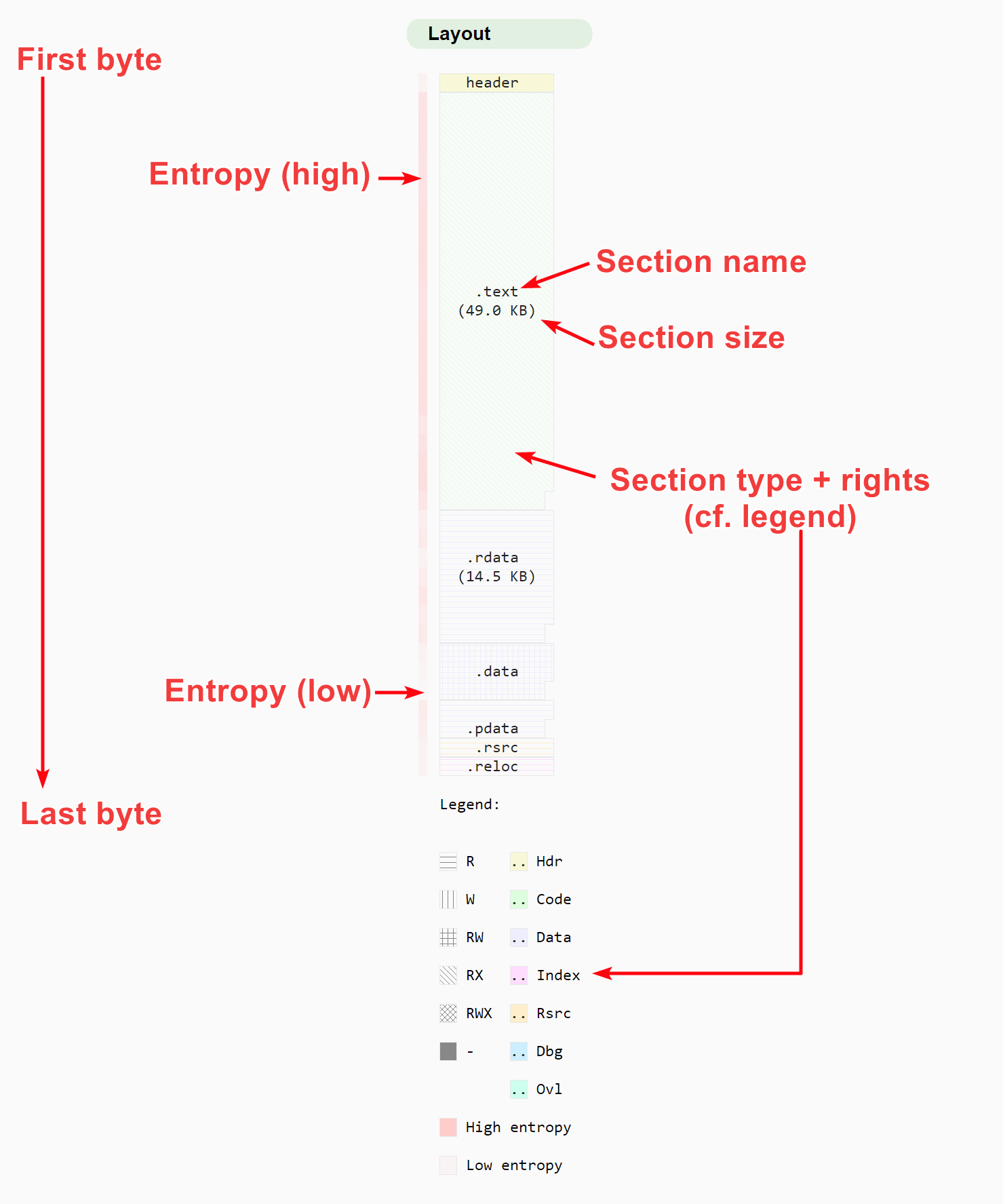
The file layout as displayed in the summary view
For most file types, this is an optional task: it just helps the user to know what the file is made of. For programs though, it is a crucial step: it will tell Malcat which part of the file are loaded in memory, and at which address. This is vital information for many analyses, such as the disassembler, function recovery, debug information parsing, string scanner, etc.
Note
If you don’t define any section, Malcat will automatically create one for you named "unparsed" and covering the whole file. On the other hand, if you add one or more sections but it/they don’t cover all the file, Malcat will automatically fill the gaps with sections named:
"header", for the section gap at the beginning of the file"gap", for all the gaps in the iddle of the file"overlay", for the section gap between the last defined section and the end of the file
In order to inform Malcat about the layout of the file, you can use the following three functions:
FileTypeAnalyzer.set_imagebase(): This will tell Malcat what is the base memory address at which the file will be loaded. Only makes sense for program loaded in memory.FileTypeAnalyzer.set_eof(): Sets the real/effective size of the current file (i.e. the size as specified in the file format headers).FileTypeAnalyzer.add_section(): Describe a new section of the file. Example:self.add_section(sname, r.foff, r.fsize, max(0, self.imagebase + r.rva), r.vsize, r = r.section["Characteristics"]["MemRead"], w = r.section["Characteristics"]["MemWrite"], x = r.section["Characteristics"]["MemExecute"], discardable = r.section["Characteristics"]["MemDiscardable"], )
Telling Malcat the real size of the current file, via FileTypeAnalyzer.set_eof(), is also recommended. During the carving process, if FileTypeAnalyzer.confirm() and FileTypeAnalyzer.set_eof() have both been called, the parsing can be interrupted earlier which improves performance.
Note
If you never call FileTypeAnalyzer.set_eof(), the last byte of the file is assumed to be either the last byte of the last yielded field/structure, or the last byte of the last section, whatever is greater.
Metadata
Parsers can also gather some metadata during the parsing process. What we call metadata are any information which gives some context about the file, such as dates, authors, versions, copyright strings, paths etc. These metadata can be very valuable for analysts when making clean/malware decisions.
Metadata in Malcat are simple key-value paires, both key and values being arbitrary strings. You can also group metadata in categories, e.g. all debug-related metadata, or all export-related metadata, which improves their presentation in the Summary view. To add a metadata, simply call the FileTypeAnalyzer.add_metadata() function, for instance:
if int(expdir["TimeDateStamp"].timestamp()) not in (0, 0xffffffff):
self.add_metadata("Exports date", expdir["TimeDateStamp"].strftime("%Y-%m-%d %H:%M:%S"), category="Exports")
The Virtual File System
Some file formats like archives or disk images embed sub-files that the user may want to extract for further analysis. Since recovering the list of files usually involves parsing the internal structures of the file format, the parser is also put in charge of this task.
From within the FileTypeAnalyzer.parse() method, you can notify Malcat of the existence of embedded files via the FileTypeAnalyzer.add_file() method. This method takes up to 5 parameters, but only the 3 first are mandatory:
vpath: the virtual path of the file, e.g. /directory/entry.txt
size: the size of the file once unpacked (or an estimate)
unpack_method_name: the method name to call (in this parser’s instance) to unpack the file.
Let us have a quick look at the ZIP parser for instance:
def parse(self, hint):
self.filesystem = {} # used internally to map a vfile path to the corresponding LocalFile ZIP structure
files_seen = set()
# ...
if tag == b"PK\x03\x04":
lfh = yield LocalFile(category=Type.HEADER)
compressed_size = lfh["CompressedSize"]
uncompressed_size = lfh["UncompressedSize"]
# ...
if "FileName" in lfh:
fn = lfh["FileName"]
if compressed_size and uncompressed_size:
if fn and not fn in files_seen:
files_seen.add(fn)
self.add_file(fn, uncompressed_size, "open") # tells Malcat about the file
self.filesystem[fn] = (lfh, compressed_size) # for us internally
There the parsers told Malcat, via the FileTypeAnalyzer.add_file() method, about all the file listed in the LocalFile structures of the ZIP archive. This will make these files be listed in the Virtual Files tab:
The virtual files tab
Now that’s all well and good, but what happens when the user double-clicks the virtual file? Well, that’s when the third parameter of FileTypeAnalyzer.add_file() comes into play: it tells Malcat which method of this parser to call in order to unpack the file. If we look into the code of ZIP parser , we can see indeed that it defines an open method:
def open(self, vfile, password=None):
lfh, compressed_size = self.filesystem.get(vfile.path, (None, None)) # recover the info we saved in parse()
if lfh is None:
raise KeyError("Unknown file path {}".format(vfile.path))
# ...
return self.unpack_manual(lfh, buf, pwd) # do the unpacking, return a bytes object
Note
You don’t have to name these method “open”, you can chose whatever name you see fit. Different files can also have different unpack/open methods.
As we can see, this open method takes two input parameters:
the absolute path of the virtual file to open (the one you gave in
FileTypeAnalyzer.add_file())an (optional) password
The method should then proceed to unpack the file and return its content as a bytes object. Since they are always called after the file parsing took place, unpack methods have access to all the structures parsed in FileTypeAnalyzer.parse().
And that’s pretty much it. If the files require a password and the one passed as parameter is wrong, the method should raise an InvalidPassword exception: this will trigger in the UI a dialog box asking the user to provide another password. Any other exception thrown from these methods are displayed to the user in a simple MessageBox.
Adding symbols
File symbols, such as PE imports or ELF exported symbols, are valuable information for analysts. It is also the responsibility of the parser, to tell Malcat which symbols are defined in the analysed file. This is done by using the method FileTypeAnalyzer.add_symbol(), which helps Malcat to associate a virtual address with a symbol name. This should also be done within the FileTypeAnalyzer.parse() method. Example:
ordinal = ordinals[i]
address = addresses[ordinal]
# add symbol
self.add_symbol(self.imagebase + address, name, malcat.FileSymbol.EXPORT)
Different types of symbols can be added, you can find the list there: malcat.FileSymbol.Type.
Advanced topics
If you want to go further, you will find here a few key facts to keep into consideration when designing your parser:
A note on performances
While writing parsers in python has a lot of advantages, it can also have an impact on performances. You may start to notice it in particular if your parser tries to yield a large number of structures. Indeed, for each structures that is yielded, the following actions will happen:
a python object will be allocated
the structure’s
types.Struct.parse()method will be calledfor every sub-field yielded by
types.Struct.parse(), python objects will be allocatedevery object will be converted to CPP, which will also lead to more allocations
The reason behind this cost is because the types.Struct class is very expressive with its types.Struct.parse() method. But sometimes, you don’t need to be expressive, like when you just want to yield simple C-style structures. This is typically the case when the structure’s content is not dependent on the actual data, i.e. the structure will always have the exact same fields.
If you happen to have such a structure, you can make your structure inherit from types.StaticStruct instead of types.Struct. types.StaticStruct are structures who’s types.StaticStruct.parse() method is called only once: the first time it is yielded. Every subsequent yield of the structure will give back the exact same structure. As a consequence, the types.StaticStruct.parse() method is now a class method, which has several implications:
when you yield sub-fields from within
types.StaticStruct.parse(),Noneis always returned (remember, the structure’s content should not depend on the file’s data)you cannot call
types.Struct.look_ahead()
But the advantages in term of performances are huge, in particular if you yield a large number of instances of the same structure through your parsing. For instance, the DirectoryEntry structure found in FAT32 volumes is repeated a lot, once for each file in the file system. And since all the fields are static, inheriting from types.StaticStruct makes sense:
class DirectoryEntry(StaticStruct):
@classmethod
def parse(cls):
filename = yield String(8, name="ShortFileName")
yield String(3, name="FileExtension") # fixed-size strings are ok, C-strings or prefixed strings are not since file data would need to be read
yield BitsField(
Bit(name="ReadOnly"),
Bit(name="Hidden"),
Bit(name="System"),
Bit(name="VolumeLabel"),
Bit(name="Directory"),
Bit(name="Archive"),
Bit(name="Device"),
name="FileAttributes")
yield UInt8(name="ExtraAttributes")
yield UInt8(name="CreationTimeFine")
yield DosDateTime(name="CreationTime")
yield DosDate(name="LastAccess")
yield UInt16(name="FirstClusterHigh")
yield DosDateTime(name="ModificationTime")
yield UInt16(name="FirstClusterLow")
size = yield UInt32(name="FileSize")
# ^-- size would be None in this case, don't read yielded values
On another topic, the magic regular expression of your parser can also have an impact on performance if poorly chosen. Indeed, we have seen that the File carving algorithm will call the parser’s FileTypeAnalyzer.parse() method every time that the magic regular expression matches. If your magic regexp is not specific enough, this could lead to a huge number of parsing attempts, which leads to a huge number of CPP -> python transitions, which is rather slow by nature.
In order to improve performances, you have two (complementary) solutions:
Choose a more precise regular expression as magic. If your file format does not have one at the beginning, you can always chose a rare one found somewhere in the middle of the file and then tell Malcat where the actual start of the file is (cf. Custom parsing start and context). This is what we do for the ISO parser for instance, since the signature is not located at the beginning of the ISO image. This will reduce the number of times your parser’s parse method is called unnecessarly.
Call
FileTypeAnalyzer.set_eof()andFileTypeAnalyzer.confirm()when you know where the file ends and you are almost sure this is a valid file. When these two functions are called, the File carving algorithm will stop the parsing earlier, saving precious CPU time. For instance, you don’t need to parse all structures and imports to tell if a PE file is a somewhat valid PE file. Parsing a few key structures and the section table is enough to know the file size and validate the file.
Custom parsing start and context
Sometimes, locating the stat of a file is not as simple as looking for a magic signature. Sometimes the magic signature is not located at the beginning of the file. Or sometimes, you need to get some information from the parent file. Take for example the InnoSetup archive: while the archive is located in the overlay of the PE file, a few key offsets are stored in a RCDATA resourced named 11111 of the parent PE installer.
In order to handle these corner cases, Malcat offers you to override a special class method named FileTypeAnalyzer.locate(). This class method is called before the actual parsing takes place to locate the real start of the file and give some extra context information via the hint return value. In this method, you should return either None to abort the parsing, or return a pair of:
the real start of the file
a hint that should be given later as parameter to your parser’s
parse()method
Let us look at a first example. The ISO format has its magic signature located at offset 0x8000 (second track). The first 0x8000 bytes are reserved and not specified. Having a regular expression to match at the start of the file is thus impossible. But we can use a marker found at offset 0x8000: \x01CD001\x01:
class ISOAnalyzer(FileTypeAnalyzer):
category = malcat.FileType.FILESYSTEM
name = "ISO"
regexp = r"(?<=\x01)CD001\x01" # this regexp is located at offset 0x8000
@classmethod
def locate(cls, curfile, offset_magic, parent_parser):
if offset_magic < 0x8001: # Note: 0x8000 + 1 because the first byte (\x01) is a look-back in the regexp (that's to improve the regexp performances)
return None # if there are not at least 0x8000 bytes preceding the magic signature, then it can't be a valid ISO file: abort
return offset_magic - 0x8001, "" # real start of ISO is regexp match offset - (0x8000 + 1)
Other times, you need some context from the parent file type. For instance, for the InnoSetup parser:
class InnoSetupAnalyzer(FileTypeAnalyzer):
category = malcat.FileType.ARCHIVE
name = "InnoSetup"
regexp = r"Inno Setup Setup Data \(.{25}\x00{16}.{13}\x5d\x00" # this regular expression can appear anywhere in the archive
@classmethod
def locate(cls, curfile, offset_magic, parent_parser):
if parent_parser is not None and parent_parser.name == "PE": # InnoSetup archives are stored in the overlay of the installer, so the parent file is ALWAYS a PE file
if "Resources.RCDATA.11111.unk.Data" in parent_parser: # the 11111 resource contains useful offsets
try:
d = parent_parser["Resources.RCDATA.11111.unk.Data"]
offsets = TSetupOffsets.deserialize(d)
# the archive is split into three parts: the uninstaller, the list of files + script and the actual file data.
# the start of the archive is the first of these 3 offsets
base = min(offsets.exe_offset, offsets.setup0_offset, offsets.setup1_offset)
return base, d.hex() # <-- we'll give the content of the resource as hex string to our parse's hint parameter
except:
return None
return None
def parse(self, hint): # hint contains the 11111's resource content (hex-encoded)
offsets = TSetupOffsets.deserialize(bytes.fromhex(hint)) # get back all the offsets
# this class describes the information found in the installer's 11111 RCDATA resource
class TSetupOffsets:
def __init__(self, id, version, total_size, exe_offset, exe_uncompressed_size, exe_crc, setup0_offset, setup1_offset, offsets_crc):
self.id = id
self.total_size = total_size
self.exe_offset = exe_offset
self.exe_uncompressed_size = exe_uncompressed_size
self.exe_crc = exe_crc
self.setup0_offset = setup0_offset
self.setup1_offset = setup1_offset
@staticmethod
def deserialize(data):
return TSetupOffsets(*struct.unpack("<12s8I", data))
And that’s it. If you have more question regarding these complex topics, don’s hesitate to contact us on discord!
The parser object
- class malcat.FileTypeAnalyzer
This is the base class of all Malcat’s file parsers. You have to inherit from it to define a new parser.
Class attributes
The following three attributes are class attributes required and used by Malcat’s parsing and carving algorithms:
- name: str
A (unique) short identifier/name for the file type, e.g. “PE” or “ISO”.
- category: malcat.FileType.Category
The category of the file type. This tells malcat which icon to use to represent the file.
- regexp: str
A regular expression using pcre2 syntax which has to match for your parser to be even called.
Parsing
- parse(hint='')
You have to override this function. It is the function which is called to perform the actual file parsing
- Parameters:
hint (str) – extra free-form context information information forwarded from the parent parser or the
locate()method.
- confirm()
Call this method from within the
parse()function to validate the file type. After calling this method, Malcat will fix the current file type to the analysed file forever, even if exceptions are later thrown by the parser.
- size()
The effective size of the current file
- Return type:
int
- jump(offset)
Move the parsing pointer to another offset so that the next yield XXX put the field/structure at this address. Only works from within
parse().- Parameters:
offset (int) – the new offset
- tell()
Returns the current parsing pointer.
- Return type:
int
- eof()
Returns True iff the current parsing pointer reached the last byte of the file
- Return type:
bool
- remaining()
Returns the number of bytes laft between the end of file and the current parsing pointer (i.e. how many bytes the parser can consume)
- Return type:
int
- __iter__()
Iterate over the list of fields/structures which have been parsed until now (sorted by offset) at the global level. Example:
for field in self: print(field.name, field.offset)
- Return type:
Iterable[malcat.FieldAccess]
- __getitem__(key)
Returns the value of the last field/structure named key (if key is a string) or the ith field/structure (if key is an int) which has been parsed at the global level.
print(self["MZ"]["AddressOfPE"])
- Parameters:
key (Union[str, int]) – the name or position of the field
- Return type:
FieldAccessfor aggregate fields, the python type for atomic fields
- at(key)
Returns an accessor to the last field/structure named key (if key is a string) or the ith field/structure (if key is an int) which has been parsed at the global level.
if self.at(0).name != "MZ": raise ValueError print(self.at(0)["AddressOfPE"])
- Parameters:
key (Union[str, int]) – the name or position of the field
- Return type:
- __contains__(name)
Returns True iff a field named name has been parsed at the global level.
if not "MZ" in self: raise ValueError
- Parameters:
name (str) – the name of the field
- Return type:
bool
- classmethod locate(class, file_object, offset_magic, parent_parser)
This class method is called before the actual parsing takes place to locate the real start of the file and give some extra context information via the hint return value. Override this method for complex file formats having a non-standard start of file or needing extra information from the parent file format.
In this method, you should return either None to abort the parsing, or return a pair of:
the real start of the file
a hint that should be given as parameter to your parser’s
parse()method
- Parameters:
class – this parser’s class
file_object (malcat.File) – the file object being parsed
offset_magic (int) – the offset in file_object where this parser’s
regexphas been foundparent_parser (malcat.FileTypeAnalyzer) – the parent file type analyser, if this parser’s instance has been invoked from the File carving process.
- Returns:
(real start of file, hint) or None
- Return type:
int, str
Layout
- add_section(name, offset, size, va=None, vsize=None, r=True, w=False, x=False, discardable=False)
Describe a new section of the file.
- Parameters:
name (str) – the name of the section, e.g. “.text” or “FileAllocationTable”
offset (int) – file offset of the start pf the section
size (int) – size of the section on disk. Can be zero.
va (int) – address of the start pf the section in memory. If None, will be assumed to be offset.
vsize (int) – size of the section in memory. Can be zero. If None, will be assumed to be size
r (bool) – True if the section as READ rights
w (bool) – True if the section as WRITE rights
x (bool) – True if the section as EXEC rights
discardable (bool) – True if the section will be discareded from memory after the file is loaded (e.g. .rsrc section or headers)
- sections: Tuple[malcat.VirtualFile]
the current list of defined sections
- set_eof(size)
Call this method from within the
parse()function to set the effective size of the current file (i.e. the size as specified in the file format headers). During the carving process, ifconfirm()andset_eof()have both been called, the parsing can be interrupted earlier which improves performance.- Parameters:
size (int) – the actual size of this file (aka offset of last bytes + 1)
Note
If you never call this function, the last byte of the file is assumed to be either the last byte of the last yielded field/structure, or the last byte of the last section, whatever is greater.
- set_imagebase(va)
Define the memory address at which the binary will be loaded. Impacts other methods such as
malcat.Analysis.r2a()andmalcat.Analysis.a2r()- Parameters:
va (int) – the memory address
- imagebase: int
the currently defined imagebase
Metadata
- add_metadata(key, value, category='')
Describe a new metadata found inside the file. Metadata are arbitrary string values that will be displayed in the Summary view to give some context to the analyst.
- Parameters:
key (str) – the name of the metadata, e.g. “Creation date”
value (str) – the content of the metadata, e.g. “2024-05-10”
category (str) – a category for the metadata (e.g “All dates”, optional)
- set_architecture(architecture)
Tells Malcat which CPU architecture should be used for the disassembly
- Parameters:
architecture (malcat.Architecture) – the CPU architecture
- architecture: malcat.Architecture
The current CPU architecture
Virtual File System
- add_file(vpath, size=0, unpack_method_name='', type='', hint='')
Add a new file to the virtual file system.
- Parameters:
vpath (str) – the virtual path of the file, e.g. /directory/entry.txt
size (int) – the size of the file (just for information, a rough estimate is also ok)
unpack_method_name (str) – the method name to call (in this parser’s instance) to unpack the file.
type (str) – you can force a given parser type to be applied by setting this file to the parser’s
name(e.g. “PNG”)hint (str) – a hint to give to the virtual file’s parser
parse()method
- files: List[malcat.VirtualFile]
Added files
Symbols
- add_symbol(memory_address, name, type=malcat.FileSymbol.EXPORT)
Add a new symbol
- Parameters:
memory_address (int) – the memory address (aka VA) of the symbol
name (str) – the name of the symbol
type (malcat.FileSymbol.Type) – type of the symbol
- symbols: Iterable[malcat.FileSymbol]
An iterator over the list of defined symbols
I/O
A few helper function to help you with parsing
- read(where=None, size=1)
Read file data at the given offset
- Parameters:
where (int) – the file offset where to read. If none,
tell()will be used.size (int) – how many bytes to read
- Return type:
bytes
- look_ahead(size=1)
Read file data at the current parsing offset. Equivalent to
self.read(self.tell(), size).- Parameters:
size (int) – how many bytes to read
- Return type:
bytes
- read_cstring_ascii(where=None, max_bytes=512)
Read a null-terminated C string at the given offset
- Parameters:
where (int) – the file offset where to read the string. If none,
tell()will be used.max_bytes (int) – maximal size of the string to return
- Return type:
str
- read_cstring_utf8(where=None, max_bytes=512)
Read a null-terminated UTF8-encoded string at the given offset
- Parameters:
where (int) – the file offset where to read the string. If none,
tell()will be used.max_bytes (int) – maximal number of bytes to read
- Return type:
str
Field Access
Within the FileTypeAnalyzer.parse() method, yielding structures/records, arrays or bitfields gives you back a malcat.FieldAccess instance. This accessor class allows you to inspect the field, its name, address, value and, for aggregate fields, access all the contained sub-fields.
Note
malcat.FieldAccess instances have the same interface as malcat.StructAccess, with the only different being that they have no address field (because the file layout is still unknown at this stage):
- class malcat.FieldAccess
Has exactly the same interface than
malcat.StructAccess, with the only different being that there is noaddressfieldAttributes
All types of fields have the following attributes and methods:
- value: depends on the field type
the value of the field. For aggregate fields, this would return itself (aka a
FieldAccessinstance) since aggregate fields have no value per se. For atomic fields, the returned type depends on the field type: int, str, datetime, etc.
- name: str
the name of the field. Example:
print(self["Directories"][0].name) >> Directories[0] print(self["Directories"][0].StreamSize.name) >> StreamSize
- offset: int
the physical address of the field. Fields can only be defined on file-backed memory, so they always have a valid physical address.
- size: int
how many bytes does the field takes on disk
- has_enum()
some atomic fields have a fixed set of values. If so, has_enum will be true
- Return type:
bool
- enum: str
the textual representation of the field’s value if the field has an enum defined (i.e.
has_enum()is True). If the field is not an enum, the empty string is returned. Example:print(self["PE"].Machine.value) >> 332 print(self["PE"].Machine.enum) >> IMAGE_FILE_MACHINE_I386
Aggregate fields
For structures/records, arrays and bitfields, you have access to the following additional methods:
- count: int
number of sub-fields/members of the aggregate. For atomic fields this attribute is still defined, but it will be always 1
- __iter__()
Iterate over all the aggregate’s members, i.e. all the bits of a bitfield, all the rows of an array or all members of a record field
sections = self["Sections"] for s in sections: print("{}: #{:x}".format(s["Name"], analysis.map.a2p(s["PointerToRawData"])))
- Returns:
iterator over the list of field members
- Return type:
iterator over
FieldAccessinstances- Raises:
Errorfor atomic fields
- __getitem__(interval)
Iterate through from the ith to the jth sub-elements of the array/record/bitfield
for s in self["Sections"][1:]: print("#{:x}: {}".format(analysis.map.a2p(s.address), s.name))
- Parameters:
interval (slice) – index interval
- Return type:
iterator over the list of members (
FieldAccess)
- __getitem__(i)
return the value of the the ith aggregate member of the field
is_executable = self["PE"]["Characteristics"][1]
- Parameters:
i (int) – position of the aggregate member to query
- Return type:
FieldAccessfor aggregate fields, the python type for atomic fields- Raises:
KeyErrorif the aggregate field has less than i members
- __getitem__(name)
return the value of the first aggregate member named name. Note that this method is not valid for arrays, since array cells don’t have names.
is_executable = self["PE"]["Characteristics"]["ExecutableImage"]
- Parameters:
name (str) – name of the member
- Return type:
FieldAccessfor aggregate fields, the python type for atomic fields- Raises:
KeyErrorif no member named name can be found
- at(name)
return an accessor to the first aggregate member named name. Note that this method is not valid for arrays, since array’s elements don’t have names.
is_executable = self["PE"]["Characteristics"].at('ExecutableImage').value
- Parameters:
name (str) – name of the member
- Return type:
FieldAccess- Raises:
KeyErrorif no member named name can be found
- at(i)
returns an accessor to the ith aggregate member
is_executable = self["PE"]["Characteristics"].at(1).value
- Parameters:
i (int) – position of the aggregate member to query
- Return type:
FieldAccess- Raises:
KeyErrorif the aggregate field has less than i members
- __getattr__(name)
return an accessor to the first aggregate member named name. Note that this method is not valid for arrays, since array cells don’t have names.
is_executable = self["PE"]["Characteristics"].ExecutableImage.value # equivalent is_executable = self["PE"]["Characteristics"].at('ExecutableImage').value # equivalent is_executable = self["PE"]["Characteristics"]['ExecutableImage']
- Parameters:
name (str) – name of the member
- Return type:
FieldAccess- Raises:
KeyErrorif no member named name can be found
Symbols
- class malcat.FileSymbol
A symbol is a name attached to a given memory address
- address: int
The memory address (aka VA) of the symbol
- name: str
Name of the symbol
- type: malcat.FileSymbol.Type
Which kind of symbol it is
- class malcat.FileSymbol.Type
- EXPORT
Anxported function. Will be used By Malcat’s CFG reconstruction algorithm as entry point
- IMPORT
An imported function / variable
- ENTRY
Entry point of a program. Note that there can be multiple entry points in one program (e.g. TLS callbacks)
- FUNCTION
An internal, non-exported function
- DATA
A variable