CFG / functions recovery
A large amount of Malcat’s power stems from its code analysis abilities. This is key not only for you fellow reverse engineers, but also for many of Malcat features such as Kesakode, our Malware identification technology.
What is CFG recovery?
Control-Flow Graph (CFG) recovery is a crucial process in reverse engineering and decompilation, where the goal is to reconstruct the control-flow graph of a binary program. This graph represents the flow of execution within the program, detailing how different parts of the code interact.
The first pitfall any CFG recovery algorithm has to overcome is how to separate the code from the data. It may sound like a simple task, but sadly we live in a von Neumann architecture world, were data and code live together in your computer’s memory. Sure, the ELF or PE file formats give you some information, such has “this is a code section” or “this contains read-only data”, but these are merely hints. You can find data in code sections (e.g. switch tables, or just everything if you’re a Delphi program) or code in data section (if you’re analysing a packer/crypter for instance).
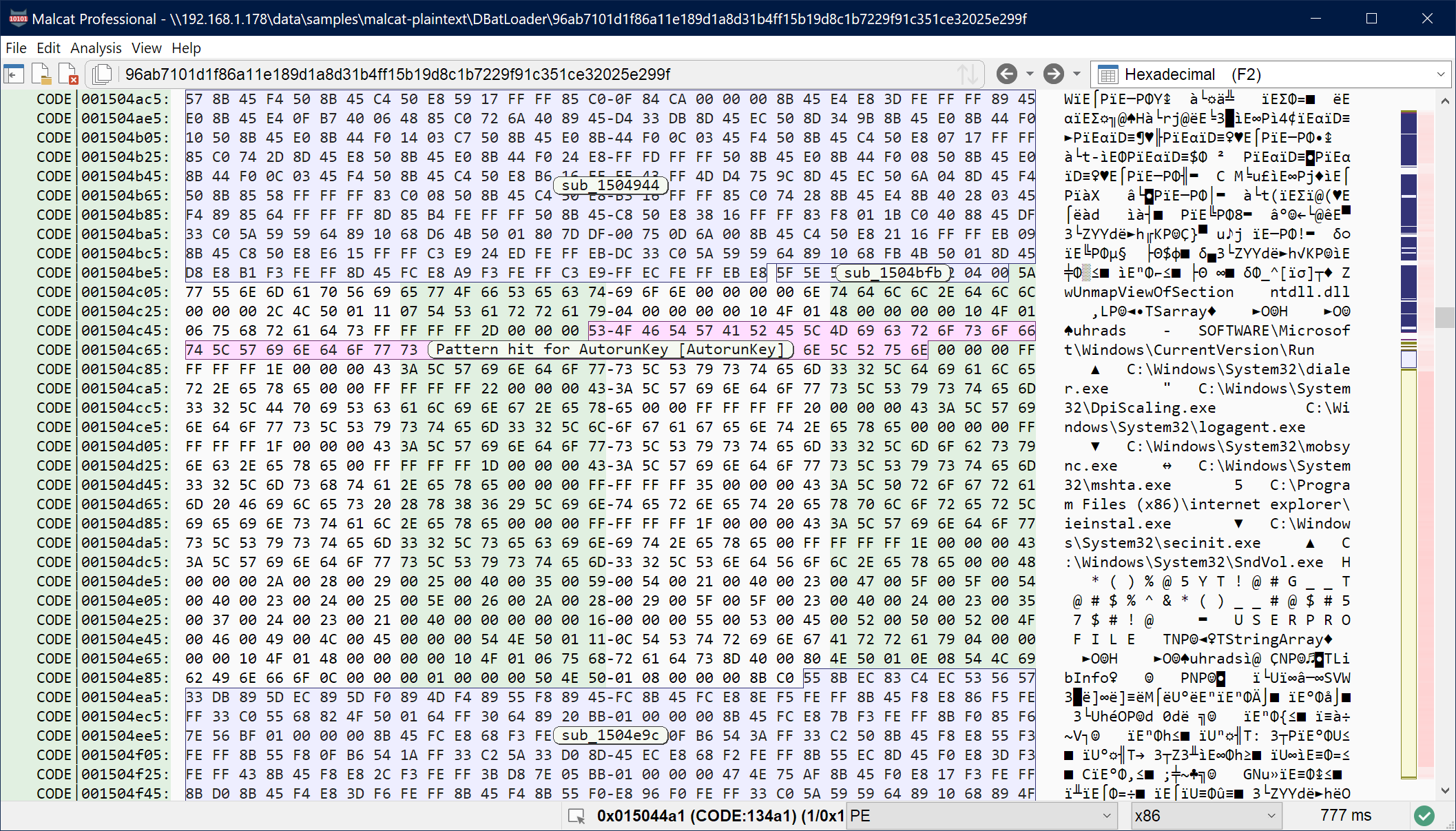
Delphi programs mix code and data in their code section (DBatLoader)
If you somehow managed to identify all the code in the program, the second challenge would be to reconstruct the control flow graph. This means following each jump and call, both static ones where the destination is encoded in the instruction (easy) and dynamic ones where the destination is computed at run time (e.g. switch tables, hard). This comes also with additional challenges, like getting the exception flow right, identifying non-returning functions, etc.
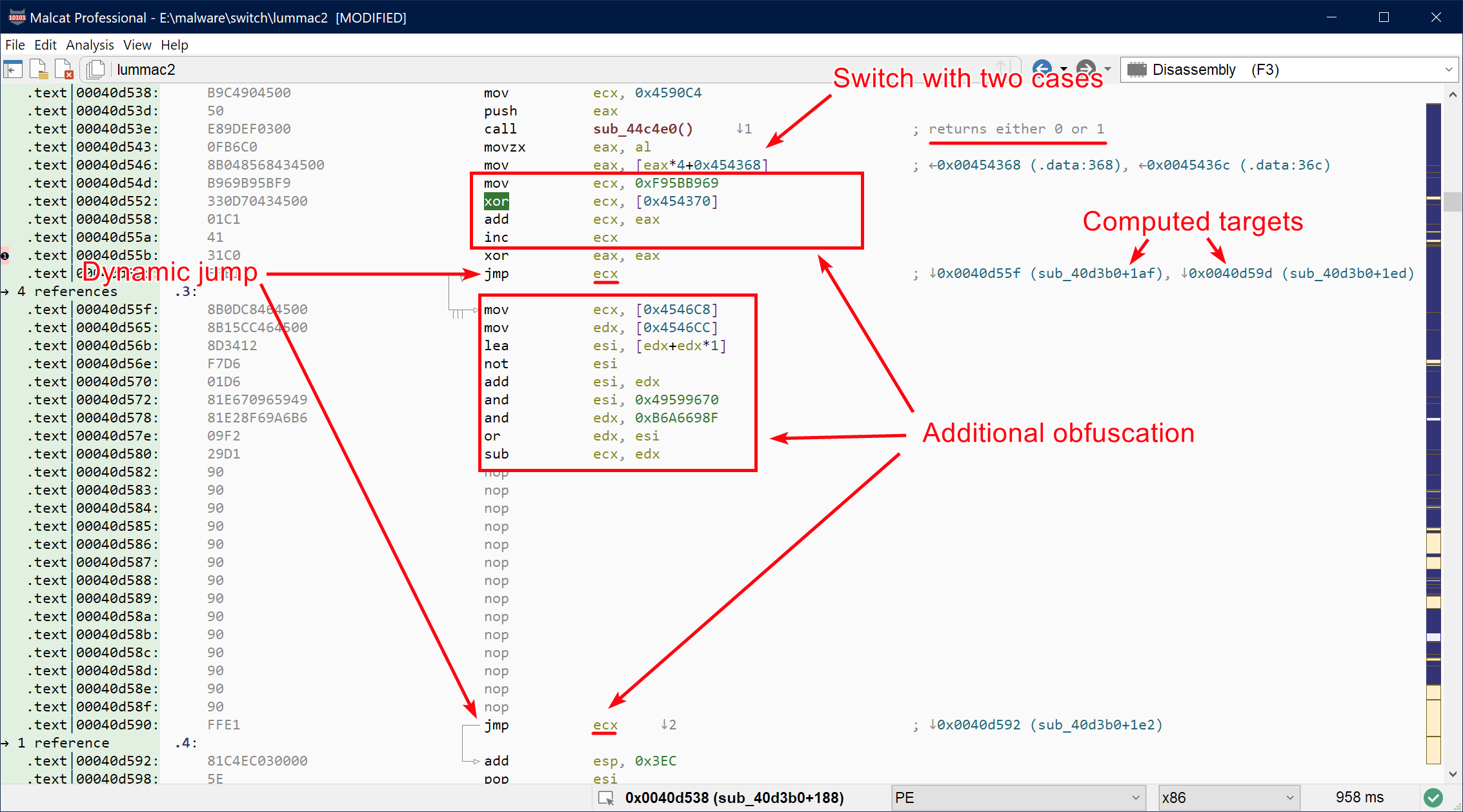
Resolving dynamic jumps in an obfuscated program (LummaC2)
Finally, the last challenge one has to face is to identify the function boundaries. This is a relatively easy task if the program comes with (debug) symbols, but it is very rarely the case in the world of malware analysis. Different algorithms can be used, that will each have to overcome common pitfalls such as terminal function identification or tail call analysis. Even then, function boundaries recovery has not always a single valid solution.
If you’re interested in this topic, I invite you to read about all these challenges (and more) in this nice introductory paper: All You Ever Wanted to Know About x86/x64 Binary Disassembly But Were Afraid to Ask. You will see a more comprehensive list of the techniques used in contemporary reverse engineering software, both commercial and open-source.
Malcat’s algorithm
Malcat’s CFG recovery algorithm is divided in three phases: a code identification phase, a CFG reconstruction phase and finally the functions recovery. Each phase is described below.
First phase: separating code from data
When Malcat starts the analysis of a program, it takes a pessimistic approach: by default everything is data. Malcat will have to be convinced to consider portions of this data as code. So the first action in Malcat’s code analysis pipeline (after the whole program range has been tagged as data) is to gather every potential code entries, such as:
File format-defined entrypoints (entrypoint, .init, TLS, etc.)
Exported functions
Functions with debug informations
RTTI vtables
Known function prologs (using pattern matching, aka regexps)
Exception handlers
Data references (i.e. following pointers found in any non-code section)
Small gaps between two already-identified functions (heuristic added in 0.9.10)
Each of these entry points candidates needs to be confirmed first. Malcat uses three different algorithms to verify that code is indeed real code.
The first heuristic is a simple validity test: the code flow is disassembled starting at the entry point candidate and following every jump and call. If invalid instructions are encountered, or if the control flow is directed to invalid addresses, the code entry address is rejected. The amount of disassembled instructions depends on the type of the entry point. Each potential code source comes with a risk factor associated, e.g. exported function addresses are relatively low-risk (i.e. there is a high chance that a function effectively starts there), while pointers found in a data section are high-risk. The higher the risk factor, the more instructions Malcat will disassemble before accepting the entry point candidate.
The second heuristic is an opcode frequency analysis. Malcat will compute the distribution of opcodes along the control flow following the entrypoint candidate. If the deviation of opcode frequencies to a previously-computed ground truth is too high, the address will be considered as data. The idea there is to reject code largely composed of very rarely used instructions.
The third and last heuristic will inspect the relationship between adjacent instructions. Malcat will compute the probability of instruction sequences to happen against a previously computed ground truth stored as a markov chain. If too many odd transitions are spotted (e.g. a cmp instruction followed by a call), the entry point candidate is rejected. Again, the number of transitions analysed depends on the associated risk factor.
Finally, validated code entry candidates are then passed to the second phase of Malcat’s CFG reconstruction algorithm: the actual build of the code flow graph, described below.
Second phase: building the graph
Building the control flow graph once we are sure that code is indeed code is relatively straightforward. Every instruction has to be followed and added to the graph. Jumps and calls are followed too. Code references (e.g. lea ecx, <address_of_SEH_handler) are also gathered and saved for a later new pass of the first phase.
Problems arise when encountering dynamic jumps. Dynamic jumps are generated on a regular basis by compilers, by the C switch instruction for instance, or via C++ virtual calls. Some malware abuse them too in order to make static analysis harder. To solve these dynamic calls, the behavior of the program needs to be emulated, at least to some extent, in order to compute the target address. Malcat uses an abstract-interpretation-like analysis in order to over-approximate the value of CPU registers and stack values at any given program point. Not all instructions are emulated, only the ones the most likely to play a role in pointer arithmetic, such as add, mul, lea, and, etc.

Switch resolution in x64 require pointer arithmetic
Value of these registers and stack variables are overapproximated using a rather task-specific abstract domain: values are first approximated using a set of values (aka VSA analysis). When a set of values is getting too big, the abstract domain is switched to a masked interval, i.e. a min-max pair with a mask value. We have found out that this abstract representation gave good results for pointer arithmetic, while being relatively efficient to compute.
These two first phases (code identification and CFG reconstruction) are run multiple times, since the CFG reconstruction may discover new code entry points candidates. Malcat will stop once a fixpoint has been reached, i.e. when no new code location has been discovered.
Third phase: function boundaries
The last step in CFG reconstruction is identifying and delimiting functions inside the global CFG. Malcat’s approach there is relatively simple, following loosely the technique described in the Nucleus paper. The idea there is to cut all call edges in the CFG and identify all connected components in the graph. Each connected component defines a function.
The simplicity of this algorithm as well as the non-reliance on pattern matching makes it not only accurate, but also compiler-agnostic. And these are good properties for Malcat, since we don’t have the man-power to deal support many compiler specifics. But as always, the devil lies in the details, and the Nucleus function identification algorithm needs to address two major challenges:
Identifying tail calls, where the compiler uses a jmp instruction instead of a call for the last function call of a function.
Dealing with non-returning functions
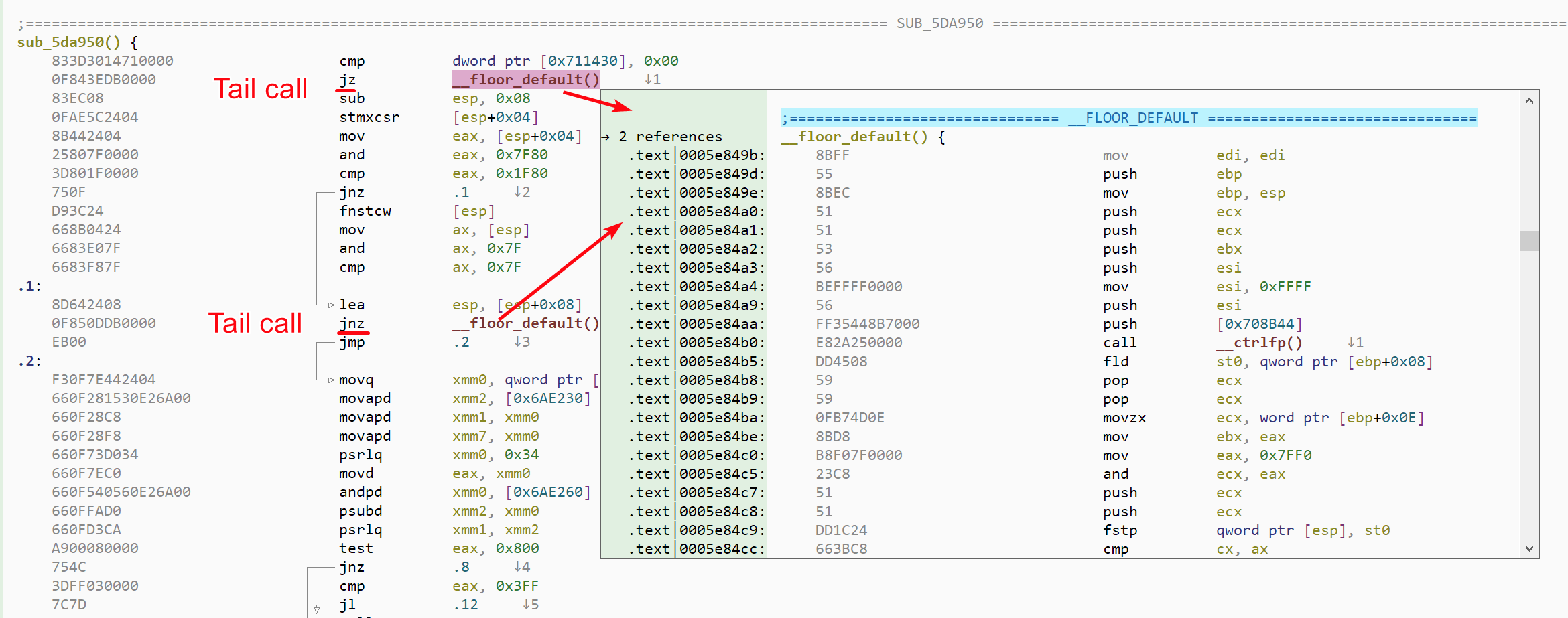
An example of tail call performed via a conditional jump
Malcat uses heuristics to solve both problems. While tail-call analysis in Malcat performs relatively well, as the results presented in the next chapter suggest, we are currently not very happy about our non-returning function identification algorithm. Some work still needs to be done there, such as building a large library of non-returning APIs. This is an area that we will improve further in the future.
How does Malcat perform?
Malcat’s main target is and will always be malware analysis, and as such our goals diverge a bit from the big boys (i.e. ghidra, binja, ida & co). We want in priority:
fast code analysis (malware triaging means looking at many programs per day)
a sound CFG recovery algorithm, resilient to code obfuscation
a good function boundaries identification for Kesakode
On the performances side, as you will see when you test the new release, the new abstract interpretation based analysis adds an overhead of about 10-15% of CPU time to the old CFG analysis present in Malcat. That’s non-negligible, but you have to put it in perspective. Malcat’s CFG analysis has always been very fast, or at least (a lot) faster than the other big RE solutions, so 15% is not a big deal at the end.
Regarding the soundness of our new code analysis, the best way to measure it is to test it against publicly available test sets. While there are many academic papers on this topic available online, we have chosen the work published in Dr. Daniel Johannes Plohmann’s thesis (Malpedia’s founder). In his thesis, he compares his own binary analysis framework (SMDA) against commercial solutions on your usual test sets (byteweight, SPEC-C) and, an original twist, on his own set of dumped malware images. Since malware analysts are looking at sandbox/process dumps on a regular basis, we figured this would make a good benchmark.
On page 128 of [the thesis]({attach}6716.pdf), you can find a function boundaries benchmark performed against the following solutions:
We have run Malcat’s new CFG recovery algorithm against this test set[^1] (special thanks to D. Plohmann for giving us access to his Malpedia57 set!) and put all numbers inside the table below:
[^1]: minus the SPEC-2006 C/C++ test set which is sadly not available anymore :(
> Note: recall is the percentage of functions rightfully discovered, i.e. how exhaustive is the analysis. A lower score means functions have been missed. Precision on the other hand is the ratio of good answers given, i.e how error-prone is the analysis. A lower score means non-functions have been identifed as functions.
| Benchmark | Compiler | Ghidra 9.1.2 | IDA Pro 7.4 | Malcat 0.9.10 | Nucleus | Smda 1.2.5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Recall | Prec. | Recall | Prec. | Recall | Prec. | Recall | Prec. | Recall | Prec. | ||
| servers (Andriesse) | gcc5.10-32 | .996 🥇 | 1.00 🥇 | .967 🥉 | .998 🥉 | .981 🥈 | .987 🥈 | .983 | .979 | .981 | .973 |
| gcc5.10-64 | .992 🥇 | 1.00 🥇 | .959 | 1.00 | .987 🥈 | .989 🥈 | .979 🥉 | .983 🥉 | .982 | .962 | |
| llvm370-32 | .766 | 1.00 | .867 | 1.00 | .975 🥈 | .991 🥈 | .985 🥇 | .993 🥇 | .985 🥉 | .958 🥉 | |
| llvm370-64 | .992 🥇 | 1.00 🥇 | .942 | 1.00 | .977 🥈 | .989 🥈 | .970 🥉 | .991 🥉 | .962 | .959 | |
| Byteweight | msvc10-32 -O1 | .804 | .952 | .835 | .996 | .952 🥈 | .957 🥈 | .975 🥉 | .923 🥉 | .992 🥇 | .935 🥇 |
| msvc10-32 -O2 | .809 | .950 | .833 | .996 | .956 🥈 | .956 🥈 | .975 🥉 | .894 🥉 | .992 🥇 | .927 🥇 | |
| msvc10-64 -O1 | .675 | .999 | .813 | .999 | .930 🥈 | .992 🥈 | .949 🥉 | .969 🥉 | .975 🥇 | .983 🥇 | |
| msvc10-64 -O2 | .703 | .999 | .811 | .999 | .933 🥈 | .992 🥈 | .948 🥉 | .938 🥉 | .972 🥇 | .981 🥇 | |
| Byteweight (PE headers zeroed) | msvc10-32 | .775 🥉 | .953 🥉 | .743 | .928 | .971 🥈 | .899 🥈 | .745 | .621 | .967 🥇 | .910 🥇 |
| msvc10-64 | .653 🥉 | .999 🥉 | .543 | .999 | .965 🥈 | .889 🥈 | .645 | .413 | .932 🥇 | .985 🥇 | |
| Malpedia57 (57 malware memory dumps) | .819 | .940 | .847 🥉 | .964 🥉 | .925 🥈 | .949 🥈 | .914 | .627 | .976 🥇 | .935 🥇 | |
At the end, we are pretty happy with these results, especially if you keep in mind that Malcat’s focus doesn’t lie in its code analysis. Sure, Malcat does not get many gold medals, but it is consistently second for all test sets. More importantly, Malcat’s function identification performances (as well as SMDA’s) do not degrade significantly when facing memory dumps and/or trashed PE files. This means Malcat should behave properly in face of obfuscated programs too, which is pretty important for our users! This is most likely due to the use of Markov chains and the very little reliance on pattern matching inside Malcat.
Note
The results shown above should be interpreted with great care:
function boundaries detection is only a small part of what a reverse engineering software does. While it is important to Malcat (because of Kesakode), stack analysis or type propagation (which are notably absent in Malcat) have a much bigger impact for deep RE sessions.
the extent of these tests is limited: they only cover x86 software, and you won’t see any fancy compilers (I would be curious to see these tests performed on Delphi programs for instance :).
they don’t take every performance criterions into account, such as memory or CPU usage, which are also important. For instance IDA has relatively low memory consumption, which is great for the analysis of big programs, while Nucleus/Binary Ninja has some room for improvement in this domain. On the contrary, Malcat is the fastest of all these software by a large margin (even if we consider all of Malcat’s additional analyses), while SMDA, being written in python, is most likely the slowest.
not all major reversing software are present: Radare is missing and Binary Ninja, while [having similiarities with Nucleus](https://binary.ninja/2017/11/06/architecture-agnostic-function-detection-in-binaries.html), is likely to get better scores than Nucleus. And the software which are present are a bit outdated too now (IDA 9 is now out, as well as Ghidra 11.3). So even if this is a good becnhmark for malware analysis, take these scores with a grain of salt.